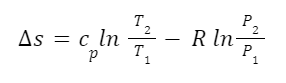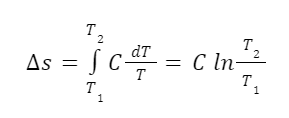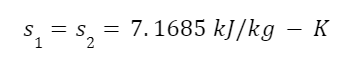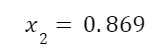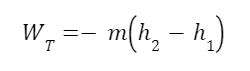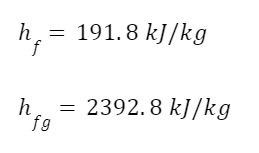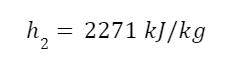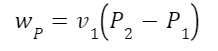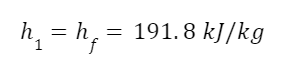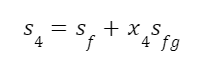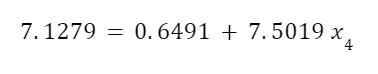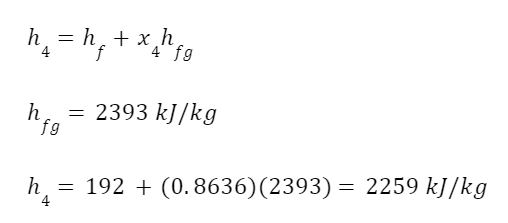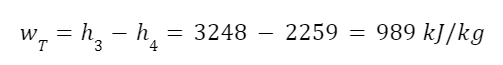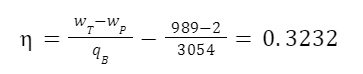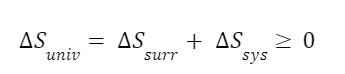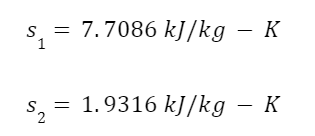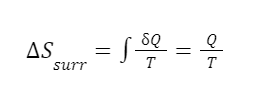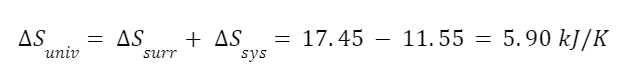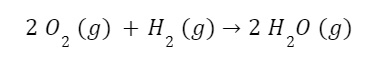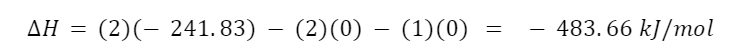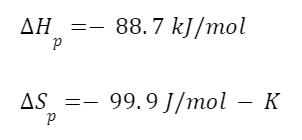Entropy is an important property in science but it can be somewhat challenging. It is commonly understood as “disorder”, which is fine as an analogy but there are better ways to think about it. As with many concepts, especially complex ones, better understanding comes with repeated use and application. Here we look at how to use and quantify entropy in applications with steam and chemical reactions.
Entropy is rather intimidating. It’s important to the sciences of physics and chemistry but it’s also highly abstract. There are, no doubt, more than a couple of students who graduate with college degrees in the physical sciences or in engineering who don’t have much of an understanding of what it is or what to do with it. We know it’s there and that it’s a thing but we’re glad not to have to think about it any more after we’ve crammed for that final exam in thermodynamics. I think one reason for that is because entropy isn’t something that we often use. And using things is how we come to understand them, or at least get used to them.
Ludwig Wittgenstein argued in his later philosophy that the way we learn words is not with definitions or representations but by using them, over and over again. We start to learn “language games” as we play them, whether as babies or as graduate students. I was telling my daughters the other day that we never really learn all the words in a language. There are lots of words we’ll never learn and that, if we happen to hear them, mean nothing to us. To use a metaphor from Wittgenstein again, when we hear these words they’re like wheels that turn without anything else turning with them. I think entropy is sometimes like this. We know it’s a thing but nothing else turns with it. I want to plug it into the mechanism. I think we can understand entropy better by using it to solve physical problems, to see how it interacts (and “turns”) with things like heat, temperature, pressure, and chemical reactions. My theory is that using entropy in this way will help us get used to it and be more comfortable with it. So that maybe it’s a little less intimidating. That’s the object of this episode.
I’ll proceed in three parts.
1. Define what entropy is
2. Apply it to problems using steam
3. Apply it to problems with chemical reactions
What is Entropy?
I’ll start with a technical definition that might be a little jarring but I promise I’ll explain it.
Entropy is a measure of the number of accessible microstates in a system that are macroscopically indistinguishable. The equation for it is:
S = k ln W
Here S is entropy, k is the Boltzmann constant, and W is the number of accessible microstates in a system that are macroscopically indistinguishable.
Most people, if they’ve heard of entropy at all, haven’t heard it described in this way, which is understandable because it’s not especially intuitive. Entropy is often described informally as “disorder”. Like how your bedroom will get progressively messier if you don’t actively keep it clean. That’s probably fine as an analogy but it is only an analogy. I prefer to dispense with the idea of disorder altogether as it relates to entropy. I think it’s generally more confusing than helpful.
But the technical, quantifiable definition of entropy is a measure of the number of accessible microstates in a system that are macroscopically indistinguishable.
S = k ln W
Entropy S has units of energy divided by temperature, I’ll use units of J/K. The Boltzmann constant k is the constant 1.38 x 10-23 J/K. The Boltzmann constant has the same units as entropy so those will cancel, leaving W as just a number with no dimensions.
W is the number of accessible microstates in a system that are macroscopically indistinguishable. So we need to talk about macrostates and microstates. An example of a macrostate is the temperature and pressure of a system. The macrostate is something we can measure with our instruments: temperature with a thermometer and pressure with a pressure gauge. But at the microscopic or molecular level the system is composed of trillions of molecules and it’s the motion of these molecules that produce what we see as temperature and pressure at a macroscopic level. The thermal energy of the system is distributed between its trillions of molecules and every possible, particular distribution of thermal energy between each of these molecules is an individual microstate. The number of ways that thermal energy of a system can be distributed among its molecules is an unfathomably huge number. But the vast majority of them make absolutely no difference at a macroscopic level. The vast majority of the different possible microstates correspond to the same macrostate and are macroscopically indistinguishable.
To dig a little further into what this looks like at the molecular level, the motion of a molecule can take the form of translation, rotation, and vibration. Actually, in monatomic molecules it only takes the form of translation, which is just its movement from one position to another. Polyatomic molecules can also undergo rotation and vibration, with the number of vibrational patterns increasing as the number of atoms increases and shape of the molecule becomes more complicated. All these possibilities for all the molecules in a system are potential microstates. And there’s a huge number of them. Huge, but also finite. A fundamental postulate of quantum mechanics is that energy is quantized. Energy levels are not continuous but actually come in discrete levels. So there is a finite number of accessible microstates, even if it’s a very huge finite number.
For a system like a piston we can set its entropy by setting its energy (U), volume (V), and number of atoms (N); its U-V-N conditions. If we know these conditions we can predict what the entropy of the system is going to be. The reason for this is that these conditions set the number of accessible microstates. The reason that the number of accessible microstates would correlate with the number of atoms and with energy should be clear enough. Obviously having more atoms in a system will make it possible for that system to be in more states. The molecules these atoms make up can undergo translation, rotation, and vibration and more energy makes more of that motion happen. The effect of volume is a little less obvious but it has to do with the amount of energy separating each energy level. When a set number of molecules expand into a larger volume the energy difference between the energy levels decreases. So there are more energy levels accessible for the same amount of energy. So the number of accessible microstates increases.
The entropies for many different substances have been calculated at various temperatures and pressures. There’s especially an abundance of data for steam, which has had the most practical need for such data in industry. Let’s look at some examples with water at standard pressure and temperature conditions. The entropy of
Solid Water (Ice): 41 J/mol-K
Liquid Water: 69.95 J/mol-K
Gas Water (Steam): 188.84 J/mol-K
One mole of water is 18 grams. So how many microstates does 18 grams of water have in each of these cases?
First, solid water (ice):
S = k ln W
41 J/K = 1.38 x 10-23 J/K * ln W
Divide 41 J/K by 1.38 x 10-23 J/K and the units cancel
ln W = 2.97 x 1024
That’s already a big number but we’re not done yet.
Raise e (about 2.718) to the power of both sides
W = 10^(1.29 x 10^24) microstates
W = 101,290,000,000,000,000,000,000,000 microstates
That is an insanely huge number.
Using the same method, the value for liquid water is:
W = 10^(2.2 x 10^24) microstates
W = 102,200,000,000,000,000,000,000,000 microstates
And the value for steam is:
W = 10^(5.94 x 10^24) microstates
W = 105,940,000,000,000,000,000,000,000 microstates
In each case the increased thermal energy makes additional microstates accessible. The fact that these are all really big numbers makes it a little difficult to see that, since these are differences in exponents, each number is astronomically larger than the previous one. Liquid water has 10^(9.1 x 10^23) times as many accessible microstates as ice. And steam has 10^(3.74 x 10^24) times as many accessible microstates as liquid water.
With these numbers in hand let’s stop a moment to think about the connection between entropy and probability. Let’s say we set the U-V-N conditions for a system of water such that it would be in the gas phase. So we have a container of steam. We saw that 18 grams of steam has 10^(5.94 x 10^24) microstates. The overwhelming majority of these microstates are macroscopically indistinguishable. In most of the microstates the distribution of the velocities of the molecules is Gaussian; they’re not all at identical velocity but they are distributed around a mean along each spatial axis. That being said, there are possible microstates with different distributions. For example, there are 10^(1.29 x 10^24) microstates in which that amount of water would be solid ice. That’s a lot! And they’re still accessible. There’s plenty of energy there to access them. And a single microstate for ice is just as probable as a single microstate for steam. But there are 10^(4.65 x 10^24) times as many microstates for steam than there are for ice. It’s not that any one microstate for steam is more probable than any one microstate for ice. It’s just that there are a lot, lot more microstates for steam. The percentage of microstates that take the form of steam is not 99% or 99.99%. It’s much, much closer than that to 100%. Under the U-V-N conditions that make those steam microstates accessible they will absolutely dominate at equilibrium.
What if we start away from equilibrium? Say we start our container with half ice and half steam by mass. But with the same U-V-N conditions for steam. So it has the same amount of energy. What will happen? The initial conditions won’t last. The ice will melt and boil until the system just flips among the vast number of microstates for steam. If the energy of the system remains constant it will never return to ice. Why? It’s not actually absolutely impossible in principle. But it’s just unimaginably improbable.
That’s what’s going on at the molecular level. Macroscopically entropy is a few levels removed from tangible, measured properties. What we see macroscopically are relations between heat flow, temperature, pressure, and volume. But we can calculate the change in entropy between states using various equations expressed in terms of these macroscopic properties that we can measure with our instruments.
For example, we can calculate the change in entropy of an ideal gas using the following equation:
Here s is entropy, cp is heat capacity at constant pressure, T is temperature, R is the ideal gas constant, and P is pressure. We can see from this equation that, all other things being equal, entropy increases with temperature and decreases with pressure. And this matches what we saw earlier. Recall that if the volume of a system of gas increases with a set quantity of material the energy difference between the energy levels decreases and there are more energy levels accessible for the same amount of energy. Under these circumstances pressure would decrease so entropy would decrease with pressure.
For solids and liquids we can assume that they are incompressible and leave off the pressure terms. So the change in entropy for a solid or liquid is given by the equation:
Let’s do an example with liquid water. What’s the change in entropy, and the increase in the number of accessible microstates, that comes from increasing the temperature of liquid water one degree Celsius? Let’s say we’re increasing 1 mole (18 grams) of water from 25 to 26 degrees Celsius. At this temperature the heat capacity of water is 75.3 J/mol-K.
Now that we have the increase in entropy we can find the increase in the number of microstates using the equation
Setting this equal to 0.252 J/mol-K
The increase is not as high as it was with phase changes, but it’s still a very big change.
We’ll wrap up the definition section here but conclude with some general intuitions we can gather from these equations and calculations:
1. All other things being equal, entropy increases with temperature.
2. All other things being equal, entropy decreases with pressure.
3. Entropy increases with phase changes from solid to liquid to gas.
Keeping these intuitions in mind will help as we move to applications with steam
Applications with Steam
The first two examples in this section are thermodynamic cycles. All thermodynamic cycles have 4 processes.
1. Compression
2. Heat addition
3. Expansion
4. Heat rejection
These processes circle back on each other so that the cycle can be repeated. Think, for example, of pistons in a car engine. Each cycle of the piston is going through each of these processes over and over again, several times per second.
There are many kinds of thermodynamic cycles. The idealized cycle is the Carnot cycle, which gives the upper limit on the efficiency of conversion from heat to work. Otto cycles and diesel cycles are the cyles used in gasoline and diesel engines. Our steam examples will be from the Rankine cycle. In a Rankine cycle the 4 processes take the following form:
1. Isentropic compression
2. Isobaric heat addition
3. Isentropic expansion
4. Isobaric heat rejection
An isobaric process is one that occurs at constant pressure. An adiabatic process is one that occurs at constant entropy.
An example of a Rankine cycle is a steam turbine or steam engine. Liquid water passes through a boiler, the steam passes through a turbine, expanding and turning the turbine, The fluid passes through a condenser, and then is pumped back to the boiler, where the cycle repeats. In such problems the fact that entropy is the same before and after expansion through the turbine reduces the number of unknown variables in our equations.
Let’s look at an example problem. Superheated steam at 6 MPa at 600 degrees Celsius expands through a turbine at a rate of 2 kg/s and drops in pressure to 10 kPa. What’s the power output from the turbine?
We can take advantage of the fact that the entropy of the fluid is the same before and after expansion. We just have to look up the entropy of superheated steam in a steam table. The entropy of steam at 6 MPa at 600 degrees Celsius is:
The entropy of the fluid before and after expansion is the same but some of it condenses. This isn’t good for the turbines but it happens nonetheless. Ideally, most of the fluid is still vapor so the ratio of the mass that is saturated vapor to the total fluid mass is called “quality”. The entropies of saturated liquid, sf, and of evaporation, sfg, are very different. So we can use algebra to calculate the quality, x2, of the fluid. The total entropy of the expanded fluid is given by the equation:
s2 we already know because the entropy of the fluid exiting the turbine is the same as that of the fluid entering the turbine. And we can look up the other values in steam tables.
Solving for quality we find that
Now that we know the quality we can find the work output from the turbine. The equation for the work output of the turbine is:
h1 and h2 and enthalpies before and after expansion. If you’re not familiar with enthalpy don’t worry about it (we’re getting into enough for now). It roughly corresponds to the substance’s energy. We can look up the enthalpy of the superheated steam in a steam table.
For the fluid leaving the turbine we need to calculate the enthalpy using the quality, since it’s part liquid, part vapor. We need the enthalpy of saturated liquid, hf, and of evaporation, hfg. The total enthalpy of the fluid leaving the turbine is given by the formula
From the steam tables
So
And now we can plug this in to get the work output of the turbine.
So here’s an example where we used the value of entropy to calculate other observable quantities in a physical system. Since the entropy was the same before and after expansion we could use that fact to calculate the quality of the fluid leaving the turbine, use quality to calculate the enthalpy of the fluid, and use the enthalpy to calculate the work output of the turbine.
A second example. Superheated steam at 2 MPa and 400 degrees Celsius expands through a turbine to 10 kPa. What’s the maximum possible efficiency from the cycle? Efficiency is work output divided by heat input. We have to input work as well to compress the fluid with the pump so that will subtract from the work output from the turbine. Let’s calculate the work used by the pump first. Pump work is:
Where v is the specific volume of water, 0.001 m3/kg. Plugging in our pressures in kPa:
So there’s our pump work input.
The enthalpy of saturated liquid is:
Plus the pump work input is:
Now we need heat input. The enthalpy of superheated steam at 2 MPa and 400 degrees Celsius is:
So the heat input required is:
The entropy before and after expansion through the turbine is the entropy of superheated steam at 2 MPa and 400 degrees Celsius is:
As in the last example, we can use this to calculate the quality of the steam with the equation:
Looking up these values in a steam table:
Plugging these in we get:
And
Now we can calculate the enthalpy of the expanded fluid.
And the work output of the turbine.
So we have the work input of the pump, the heat input of the boiler, and the work output of the turbine. The maximum possible efficiency is:
So efficiency is 32.32%.
Again, we used entropy to get quality, quality to get enthalpy, enthalpy to get work, and work to get efficiency. In this example we didn’t even need the mass flux of the system. Everything was on a per kilogram basis. But that was sufficient to calculate efficiency.
One last example with steam. The second law of thermodynamics has various forms. One form is that the entropy of the universe can never decrease. It is certainly not the case that entropy can never decrease at all. Entropy decreases all the time within certain systems. In fact, all the remaining examples in this episode will be cases in which entropy decreases within certain systems. But the total entropy of the universe cannot decrease. Any decrease in entropy must have a corresponding increase in entropy somewhere else. It’s easier to see this in terms of an entropy balance.
The entropy change in a system can be negative but the balance of the change in system entropy, entropy in, entropy out, and entropy of the surroundings will never be negative. We can look at the change of entropy of the universe as a function of the entropy change of a system and the entropy change of the system’s surroundings.
So let’s look at an example. Take 2 kg of superheated steam at 400 degrees Celsius and 600 kPa and condense it by pulling heat out of the system. The surroundings have a constant temperature of 25 degrees Celsius. From steam tables the entropy of the superheated steam and saturated steam are:
With these values we can calculate the change in entropy inside the system using the following equation;
The entropy decreases inside the system. Nothing wrong with this. Entropy can definitely decrease locally. But what happens in the surroundings? We condensed the steam by pulling heat out of the system and into the surroundings. So there is positive heat flow, Q, out into the surroundings. We can find the change in entropy in the surroundings using the equation:
We know the surroundings have a constant temperature, so we know T. We just need the heat flow Q. We can calculate the heat flow into the surroundings by calculating the heat flow out of the system using the equation
So we need the enthalpies of the superheated steam and saturated steam.
And plugging these in
Q = mΔh=(2)3270.2-670.6=5199 J
Now that we have Q we can find the change in entropy in the surroundings:
The entropy of the surroundings increases. And the total entropy change of the universe is:
So even though entropy decreases in the system the total entropy change in the universe is positive.
I like these examples with steam because they’re very readily calculable. The thermodynamics of steam engines have been extensively studied for over 200 years, with scientists and engineers gathering empirical data. So we have abundant data on entropy values for steam in steam tables. I actually think just flipping through steam tables and looking at the patterns is a good way to get a grasp on the way entropy works. Maybe it’s not something you’d do for light reading on the beach but if you’re ever unable to fall asleep you might give it a try.
With these examples we’ve looked at entropy for a single substance, water, at different temperatures, pressures, and phases, and observed the differences of the value of entropy at these different states.
To review some general observations:
1. All other things being equal, entropy increases with temperature.
2. All other things being equal, entropy decreases with pressure.
3. Entropy increases with phase changes from solid to liquid to gas.
In the next section we’ll look at entropies for changing substances in chemical reactions.
Applications with Chemical Reactions
The most important equation for the thermodynamics of chemical reactions is the Gibbs Free Energy equation:
ΔG=ΔH-TΔS
Where H, T, S are enthalpy, temperature, and entropy. ΔG is the change in Gibbs free energy. Gibbs free energy is a thermodynamic potential. It is minimized when a system reaches chemical equilibrium. For a reaction to be spontaneous the value for ΔG has to be negative, meaning that during the reaction the Gibbs free energy is decreasing and moving closer to equilibrium.
We can see from the Gibbs free energy equation
ΔG=ΔH-TΔS
That the value of the change in Gibbs free energy is influenced by both enthalpy and entropy. The change in enthalpy tells us whether a reaction is exothermic (negative ΔH) or endothermic (positive ΔH). Exothermic reactions release heat while endothermic reactions absorb heat. This has to do with the total change in the chemical bond energies in all the reactants against all the products. In exothermic reactions the energy released from breaking chemical bonds is greater than the energy used to form new chemical bonds. This extra energy is converted to heat. We can see from the Gibbs free energy equation that exothermic reactions are more thermodynamically favored. Nevertheless, entropy can override enthalpy.
The minus sign in front of the TS term tells us that an increase in entropy where ΔS is positive will be more thermodynamically favored. This makes sense with what we know about entropy from the second law of thermodynamics and from statistical mechanics. The effect is proportional to temperature. At low temperatures entropy won’t have much influence and enthalpy will dominate. But at higher temperatures entropy will start to dominate and override enthalpic effects. This makes it possible for endothermic reactions to proceed spontaneously. If the increase in entropy for a chemical reaction is large enough and the temperature is high enough endothermic reactions can proceed spontaneously, even though the energy required to form the chemical bonds of the products is more than the energy released from the chemical bonds in the reactants.
Let’s look at an example. The chemical reaction for the production of water from oxygen and hydrogen is:
We can look up the enthalpies and entropies of the reactants and products in chemical reference literature. What we need are the standard enthalpies of formation and the standard molar entropies of each of the components.
The standard enthalpies of formation of oxygen and hydrogen are both 0 kJ/mol. By definition, all elements in their standard states have a standard enthalpy of formation of zero. The standard enthalpy of formation for water is -241.83 kJ/mol. The total change in enthalpy for this reaction is
It’s negative which means that the reaction is exothermic and enthalpically favored.
The standard molar entropies for hydrogen, oxygen, and water are, respectively, 130.59 J/mol-K, 205.03 J/mol-K, and 188.84 J/mol-K. The total change in entropy for this reaction is
It’s negative so entropy decreases in this reaction, which means the reaction is entropically disfavored. So enthalpy and entropy oppose each other in this reaction. Which will dominate depends on temperature? At 25 degrees Celsius (298 K) the change in Gibbs free energy is
The reaction is thermodynamically favored. Even though entropy is reduced in this reaction, at this temperature that effect is overwhelmed by the favorable reduction in enthalpy as chemical bond energy of the reactants is released as thermal energy.
Where’s the tradeoff point where entropy overtakes enthalpy? This is a question commonly addressed in polymer chemistry with what’s called the ceiling temperature. Polymers are macromolecules in which smaller molecular constituents called monomers are consolidated into larger molecules. We can see intuitively that this kind of molecular consolidation constitutes a reduction in entropy. It corresponds with the rough analogy of greater order from “disorder” as disparate parts are assembled into a more organized totality. And that analogy isn’t bad. So in polymer production it’s important to run polymerization reactions at temperatures where exothermic, enthalpy effects dominate. The upper end of this temperature range is the ceiling temperature.
The ceiling temperature is easily calculable from the Gibbs free energy equation for polymerization
Set ΔGp to zero.
And solve for Tc
At this temperature enthalpic and entropic effects are balanced. Below this temperature polymerization can proceed spontaneously. Above this temperature depolymerization can proceed spontaneously.
Here’s an example using polyethylene. The enthalpies and entropies of polymerization for polyethylene are
Using our equation for the ceiling temperature we find
So for a polyethylene polymerization reaction you want to run the reaction below 610 degrees Celsius so that the exothermic, enthalpic benefit overcomes your decrease in entropy.
Conclusion
A friend and I used to get together on weekends to take turns playing the piano, sight reading music. We were both pretty good at it and could play songs reasonably well on a first pass, even though we’d never played or seen the music before. One time when someone was watching us she asked, “How do you do that?” My friend had a good explanation I think. He explained it as familiarity with the patterns of music and the piano. When you spend years playing songs and practicing scales you just come to know how things work. Another friend of mine said something similar about watching chess games. He could easily memorize entire games of chess because he knew the kinds of moves that players would tend to make. John Von Neumann once said: “In mathematics you don’t understand things. You just get used to them.” I would change that slightly to say that you understand things by getting used to them. Also true for thermodynamics. Entropy is a complex property and one that’s not easy to understand. But I think it’s easiest to get a grasp on it by using it.
Noether’s theorem is an important theorem that relates invariance of space-time transformations to the laws of conservation: space-translation invariance to the conservation of linear momentum, space-rotation invariance to the conservation of angular momentum, and time-translation invariance to the conservation of energy. The models of physics are point-of-view invariant: physical models cannot depend on any particular position in space or moment in time.
A video version of this episode showing the equations is available on YouTube.
Where do the laws of physics come from? This question is the subtitle of Victor Stenger’s 2006 book Comprehensible Cosmos. I think this question is one version of the more general guiding question of my whole intellectual life: why are things the way they are? Stenger has a very interesting response to this question, which is based on what he calls principle of point-of-view invariance “The models of physics cannot depend on any particular point of view.”
The path from this principle to the laws of physics goes through an important theorem known as Noether’s Theorem. This theorem was developed by Emmy Noether in 1918. Put briefly, the theorem says that symmetries in a system generate conserved quantities. Anyone who’s studied (and remembers) physics will know of the conservation of momentum, conservation of angular momentum, and the conservation of energy. These conservation laws are absolutely foundational. And what’s remarkable is that there’s a reason for them. These conservation laws come from symmetries. The conservation of momentum, angular momentum, and energy come from symmetries of translation, rotation, and time.
Stenger puts it this way: “In any space-time model possessing time-translation invariance, energy must be conserved. In any space-time model possessing space-translation invariance, linear momentum must be conserved. In any space-time model possessing space-rotation invariance, angular momentum must be conserved. Thus, the conservation principles follow from point-of-view invariance. If you wish to build a model using space and time as a framework, and you formulate that model so as to be space-time symmetric, then that model will automatically contain what are usually regarded as the three most important ‘laws’ of physics, the three conservation principles.”
To me this is quite remarkable. But maybe I’m just easily impressed. So I went online to see how others view all this. I looked up on Quora responses to the question:“What is the significance of Noether’s theorem?” Here are some of the responses:
“I think it is almost the thing that makes sense of physics. Physics is based on a large number of conservation rules – conservation of energy, momentum etc. Without Noether’s Theorem, all you can say is that they are conserved – they are just givens. With the Theorem, you can say that they arise from the symmetries of the space we live in. [In] a space which did not have these symmetries… these conservations would be so different from the space we know as to be unrecognizable. It derives the otherwise arbitrary conservation rules from intuitively understood symmetries. Brilliant.” (Alec Cawley)
“Most of fundamental physics could be interpreted as positing a symmetry, then handing that symmetry off to Ms. Noether and asking her to tell us what the resulting physics is. In other words, without Noether’s Theorem, there wouldn’t be most of modern physics.” (Brent Follin, PhD in Theoretical Cosmology)
And my favorite.
“It’s a matter of life and death! Being a Physics student, the Noether’s theorem is extremely important with everything I do. If it were falsified, the whole structure of modern physics would crumble!” (Abhijeet Borkar, PhD in Physics (Astrophysics))
So it’s a pretty big deal. Hopefully that sparks some interest. Now let’s dig into it and see how it works.
Invariance and Transformations
First, let’s revisit this idea of point-of-view invariance. One of the first things you do in a physics problem is define your coordinates. If you’re on the surface of the Earth you usually set one axis pointing up from the center of the Earth. This is what we’re used to thinking of as “up”. That’s because in our everyday experience there pragmatically is an obvious coordinate system to use. There’s an up and a down. But that’s because we reference our everyday experience relative to Earth, which we’re living on. But we know, at least since the Copernican revolution, that this coordinate system isn’t absolute. The Earth isn’t the center of the universe, even if it is the center of our lived experience. But it’s not just that. There is no center of the universe at all. There’s no absolute up or down.
That doesn’t mean that we don’t use coordinates. Of course we do. We have to. But it does mean that the coordinate system we use is not absolute. We’ll usually use one that makes things easy for our calculations. But the system we represent in one coordinate system can also be represented in a different coordinate system.
This is easy to see with vectors. Let’s represent a vector on an x-y Cartesian coordinate system. The vector will start from the origin (0,0) and go out to point (4,3). What’s the magnitude of this vector? We calculate that by the equation:
Now let’s change the coordinate system shifting it 2 to the right and 7 up. Now this same vector starts at (-2,-7) and goes out to (2,-4). What’s the magnitude?
Now let’s go back to the first coordinate system and rotate it 30 degrees counter-clockwise. 30 degrees in radians is π/6 radians. We make this transformation using the rotation matrix
R = [[cos θ,-sin θ], [sin θ, cos θ]]
And multiply R by our vector [[x],[y]].
The result is
Rv = [[x cos θ – y sin θ], [x sin θ + y cos θ]]
Rv = [[3/2 * √(3) – 2], [3/2 * 2 x √(3)]]
Rv = [0.598], [4.964]]
For our transformation θ is π/6 radians. Our new vector coordinates are (0,0) and approximately (0.598,4.964). Now the moment of truth, after all of that. What’s the magnitude? It’s
When we look at this visually, it’s actually not surprising. The vector stays the same in all these cases. It’s just the coordinate system that’s moving around. This is the basic idea of invariance. And I think it gives a general sense about how something can remain constant if it doesn’t depend on these coordinate system transformations.
The Lagrangian
Before getting to Noether’s Theorem itself, we need to talk about the Lagrangian because Noether’s Theorem is expressed in terms of it. The Lagrangian is a function that describes the state of a system and is equal to the difference between the total kinetic energy, T, and the total potential energy, V, of a system.
L = T – V
The Lagrangian is used in Lagrangian mechanics and is a different way of looking at systems than Newtonian mechanics. Instead of looking at forces, as in Newtonian mechanics, in Lagrangian mechanics we’re looking at energies. The Lagrangian is a function of spatial coordinates and their derivatives with respect to time. Spatial coordinates could be the familiar Cartesian x,y,z coordinates but it’s customary to generalize these with a single variable. For example, q. For multiple spatial coordinates we can just number them off, q = {q1, q2,…, qn]. The time derivative of q is, q̇. The time derivative of a spatial coordinate is velocity.
So some of the familiar quantities from Newtonian mechanics will be expressed differently in Lagrangian mechanics. Most notably, momentum. In Newtonian mechanics we express momentum as mass times velocity.
p = mv
To express this in terms of a Lagrangian let’s change v to q̇. So,
p = mq̇
Now the Lagrangian is the difference between kinetic energy and potential energy.
L = T – V
Kinetic energy is
T = 1/2 mv^2
Or
T = 1/2 m q̇^2
So we can rewrite the Lagrangian as
L = 1/2 mq̇^2 – V
Now taking the derivative with respect to q̇
δL/δq̇ = mq̇
And mq̇ = p, so
p = δL/δq̇
And that’s the equation for momentum in terms of the Lagrangian.
p = δL/δq̇
So momentum is the derivative of the Lagrangian with respect to velocity. Also the derivative of the kinetic energy with respect to velocity.
The Hamiltonian
Another function I want to go over before moving on to Noether, and that’s the Hamiltonian function. The Hamiltonian is similar to the Lagrangian, except that it’s the sum of kinetic energy and potential instead of the difference between them.
H = T + V
The Hamiltonian is the total energy of the system. And we can express this in terms of the Lagrangian. Since L = T – V we can express the potential energy as
V = T – L
Substituting this into the Hamiltonian
H = T + V
H = T + (T – L)
H = 2T – L
H = 2(1/2 mq̇^2) – L
H = (mq̇)q̇ – L
Since p = mq̇
H = pq̇ – L
And since also p = δL/δq̇
H = (δL/δq̇)q̇ – L
This is the expression for the total energy in terms of the Lagrangian.
H = (δL/δq̇)q̇ – L
The Lagrange-Euler Equation of Motion
One more equation we should introduce before getting into Noether’s theorem is the Lagrange-Euler equation, also called the equation of motion. This has the form
d/dt (δL/δq̇) = δL/δq
What is this equation saying? Let’s translate this out of the Lagrangian form into the more familiar Newtonian quantities. An equivalent form of this equation is:
dp/dt = -δV/δq = F
d(mv)/dt = F
ma = F
This is Newton’s second law. It’s just expressed in a different form with the Lagrangian, which again is:
d/dt (δL/δq̇) = δL/δq
We’ll be plugging this equation into a lot of things in the foregoing so it’s important.
Noether’s Theorem
Now, let’s move to Noether’s theorem. We’ll look at Noether’s theorem for the conservation of momentum, the conservation of angular momentum, and for the conservation of energy.
We start with the Lagrangian as a function of position, q, and velocity, q̇.
L(q, q̇)
What we’re going to do is apply the following transformation on q and q̇.
q → q(s)
q̇ → q̇(s)
If our Lagrangian has symmetry it should not change under this transformation to s. Expressed mathematically this means
d/ds L(q(s), q̇(s)) = 0
Let’s propose that under this transformation that there is a conserved quantity, C, of the following form:
C = (δL/δq̇)(δq/δs)
And since it is a conserved quantity it does not change over time. That is
dC/dt = 0
And here’s the proof for that. Take the proposed conserved quantity C and take the time derivative of it.
C = (δL/δq̇)(δq/δs)
dC/dt = d/dt ((δL/δq̇)(δq/δs))
Since we have two variables, q and q̇, we need to apply the product rule:
Now, recall the Euler-Lagrange equation of motion.
d/dt (δL/δq̇) = δL/δq
We’re going to plug that in here to get.
dC/dt = (δL/δq)(δq/δs) + (δL/δq̇)(δq̇/δs)
What do we have here? The right hand side of this equation is what we get when we apply the chain rule to the derivative of the Lagrangian with respect to s.
So what’s been proved here is that if the Lagrangian, L, does not change with respect to transformation, s, than the conserved quantity, C, doesn’t either.
That’s Noether’s Theorem. Now let’s look at some applications, examples of conserved quantities that result from different symmetries.
Conservation of Linear Momentum
To get the conservation of linear momentum we’re going to say that the Lagrangian is symmetric under continuous translations in space. Our spatial coordinates are
q = {q1, q2,…, qn].
And we’ll apply the transformation
q → q(s)
where
q(s) = q + s
So we’re just sliding our coordinate system over by an interval, s.
The conserved quantity C is
C = (δL/δq̇)(δq/δs)
Taking the derivative of q with respect to s
δq/δs = δ/δs (q + s) = 1
So C becomes
C = (δL/δq̇) = p
Which is momentum. So when we apply the spatial transformation
q à q(s)
The conserved quantity, C, is momentum, p. In other words, the conservation of momentum results from symmetry in space. To give some interpretation, this means that the system has no dependence on where it is in space. It’s not being acted upon by any external forces. If there were an external force then it would depend on it’s location in space.
Recall that force is equal to
F = ma
F = m(dv/dt)
F = d/dt (mv)
F = dp/dt
Force is equal to the rate of change in momentum with respect to time. So clearly if there is a non-zero external force acting on the system momentum is not constant.
If there is an applied force external to the system, like with a spring, then momentum is obviously not conserved. And with such forces location makes a difference. With a spring it matters how much the spring is stretched. So momentum is not conserved in such cases where there’s not symmetry in space for that system. But in systems that do have symmetry in space, momentum is conserved.
Conservation of Angular Momentum
To get the conservation of angular momentum we’re going to say that the Lagrangian is symmetric under continuous rotations in space.
We apply the transformation.
q → q(s)
In which case s is some angle of rotation. This is a two-dimensional case where q is represented by the matrix
[[q1],[q2]]
We make this transformation using the rotation matrix
That’s from Taylor’s series expansion to the first order. This makes the rotation matrix is equal to
[[1, -s], [s, 1]]
So the transformation is
[[1, -s], [s, 1]] * [[q1],[q2]]
The result of this transformation is that
q1 → q1 – s * q2
q2 → q2 + s * q1
For reasons that will be clear shortly, let’s differentiate these.
dq1/ds = -q2
dq2/ds = q1
Now let’s bring in our conserved quantity, C
C = (δL/δq̇)(δq/δs)
And since
q = {q1,q1}
C = (δL/δq̇1)(δq1/δs) + (δL/δq̇2)(δq2/δs)
Or in terms of momentum, p
C = p1 * (δq1/δs) + p2 * (δq2/δs)
The derivatives in this equation are equal to the derivatives we just calculated for q1(s) and q2(s). So, plugging those in:
C = q1 * p2 – q2 * p1
And this is equal to the cross product
C = q x p
Which is angular momentum L. Angular momentum is equal to the cross product of linear momentum and the position vector. So
C = L
The conserved quantity, C, is angular momentum, L. In other words angular momentum results from symmetry of rotation. To give some interpretation again, this is the condition in which the system has no external rotational forces, i.e. torque. To use the example of a spring again, if this were a system where we’re winding up a torsion spring then angular position very much matters. The tighter we wind it up the higher the torque. In that kind of system angular momentum is not conserved. But in the absence of that kind of torque, angular position and rotation don’t matter. So angular momentum is conserved.
Conservation of Energy
To get the conservation of energy we’re going to say that the Lagrangian is symmetric in time. So we have our Lagrangian
L(q, q̇)
And we’re going to say that it doesn’t change with time
dL/dt = 0
Let’s see what follows from this. First let’s to the derivative of the Lagrangian with respect to time. To do this we apply the chain rule.
So we can plug that in to get this more compact result:
dL/dt = d/dt (q̇ * (δL/δq̇))
Rearranging we get:
0 = d/dt (q̇ * (δL/δq̇) – L)
Maybe this looks familiar. Recall that the Hamiltonian, which is equal to the sum of kinetic and potential energy has the following form, expressed in terms of the Lagrangian.
H = (δL/δq̇)q̇ – L
So we can plug this into our equation to get
d/dt (H) = 0
Let’s go ahead express this in terms of kinetic energy, T, and potential energy, V.
H = T + V
d/dt (T + V) = 0
So from our starting condition
dL/dt = 0
We get
d/dt (T + V) = 0
If we set the condition where the Lagrangian doesn’t change with time then the total energy is conserved. This is the Noether symmetry-conservation relation.
What would it be like if things weren’t this way? Under time symmetry things like the gravitational constant and the masses of fundamental particles are constant across time. What if they weren’t? An object elevated above the Earth’s surface has potential energy
V = mgh
Where m is mass, g is acceleration due to gravity, and h is height. Acceleration due to gravity is a function of the gravitational constant G.
g = – GM/r^2
Where M is the mass of the gravitational field source, like the Earth, and r is the distance from the center of the Earth. For the elevated object in our example, none of these values is changing. But what if we could change the gravitational constant G? Say we increase it. Now acceleration due to gravity, g, is higher and potential energy, V, is higher. We’ve created energy from nowhere.
Or another example. At one moment in time you throw a ball up into the air with a certain velocity. So it starts off with a kinetic energy that gets converted to potential energy as it goes up into the sky. But then right as it reaches its highest point you turn the gravitational constant, G, way up and the ball slams to the ground at a much faster velocity than you started with. Again, we’ve created energy from nowhere.
But that doesn’t happen because the laws of physics don’t change over time.
Philosophical reflections
If you were to create a universe how would you do it? I don’t know how to create a universe but if I did my inclination would be to make it as self-designing as possible. Set a few basic rules and let things develop from there. This seems to be the most efficient and elegant way to configure things. I think what makes Noether’s Theorem so marvelous is that we get a great deal of purchase from a rather simple principle: symmetry.
This reminds me a little of what Immanuel Kant tried to do in his moral philosophy. In his 1785 Groundwork of the Metaphysics of Morals he proposed that all moral principles could be derived from one master principle, called the categorical imperative, which was the following:
“Act only according to that maxim whereby you can, at the same time, will that it should become a universal law.”
This is also known as the principle of universalizability. This reminds me of Noether’s Theorem in two ways. First, it’s a simple principle from which others can be derived. Second, it’s a principle of universalizability. We could say that Kant is making his ethics point-of-view invariant. I should act only according to a maxim that could be a universal law, that is not only applicable to me, but to anyone. That’s what it means for it to be universalizable.
In Comprehensible Cosmos Victor Stenger also proposed a principle of universalizability, but for physics. “The models of physics cannot depend on any particular point of view.” That’s the principle of point-of-view invariance. Stenger says of this principle:
“Physics is formulated in such a way to assure, as best as possible, that it not depend on any particular point of view or reference frame. This helps make possible, but does not guarantee, that physical models faithfully describe an objective reality, whatever that may be… When we insist that our models be the same for all points of view, then the most important laws of physics, as we know them, appear naturally. The great conservation principles of energy and momentum (linear and angular) are required in any model that is based on space and time, formulated to be independent of the specific coordinate system used to represent a given set of data. Other conservation principles arise when we introduce additional, more abstract dimensions. The dynamical forces that account for the interactions between bodies will be seen as theoretical constructs introduced into the theory to preserve that theory’s independence of point of view.”
Sort of like Kant’s principle of universalizability, point-of-view invariance keeps us honest. Repeatability of experiments by multiple observers, holding constant only those factors relevant to the experiment, is what ought to finally convince others of the validity of our observations. It won’t do much good if I have a singular experience that only I observe that, in other words, is not universalizable, not point-of-view invariant, but rather strictly tied to me and my point of view. That’s not to say that we don’t have private, subjective experiences that are real. They’re just phenomena of a different nature. Here’s more from Stenger on this point:
“So, where does point-of-view invariance come from? It comes simply from the apparent existence of an objective reality—independent of its detailed structure. Indeed, the success of point-of-view invariance can be said to provide evidence for the existence of an objective reality. Our dreams are not point-of-view invariant. If the Universe were all in our heads, our models would not be point-of-view invariant. Point-of-view invariance generally is used to predict what an observer in a second reference frame will measure given the measurements made in the first reference frame.”
I think that’s well put. And that line that “Our dreams are not point-of-view invariant” is one I think about a lot.
Noether’s Theorem is absolutely foundational. It’s been said that Noether’s theorem is second only to the Pythagorean theorem in its importance for modern physics. It’s remarkable that just one, compact principle can produce so much of what we observe in the world.
Reference Material
Baez, J. (2020b, February 17). Noether’s Theorem in a Nutshell. University of California, Riverside. Retrieved March 25, 2022, from https://math.ucr.edu/home/baez/noether.html
This is the second episode in a series on philosophy of structure and focuses on the nature of structure in music in particular. Topics covered include the physics of sound, the wave equation, overtones, Fourier transforms, physiology of the inner ear, intervals, chords, group theory, modular arithmetic, transformations, invariance, musical forms, a Borgesian musical Library of Babel (Library of Vienna), musical phenomenology, serialism, and artificial neural networks. The overall objective of the series is to find patterns in structures across multiple fields, like music, to understand a general structure of structure.
This is the second episode in a series on a philosophy of structure. In the previous and first episode I gave a general overview of structure and some of the ideas I was looking to develop. With this episode I’ll start to get into specific fields in which structure plays a significant role. The first I’d like to look at is music.
I’d like to look at music at three levels:
1. at the level of physics, acoustics, and physiology 2. at the level of musical theory, and 3. at the level of musical expressivity and sensitivity.
Each level has its own set of structures. And between levels a structure at lower level will get wrapped up and translated into a new kind of element in the structures of a higher level; for example, in the move from physical frequencies to musical pitches. There’s some homology in this to modular programming, in which lower-level operations in a computer program are performed by modules, or subroutines, programs within programs.
One useful distinction that will come into play is between two senses of sound, as I will use them.
In one sense sound is a purely objective thing or event that occurs independent of any human perception. This is physical sound, vibration that propagates as a wave of pressure changes through a transmission medium like air. So if a tree falls in a forest and no one hears it does it make a sound? In this first sense, yes. Sound is just the vibration propagating as a wave through the air in the forest. Doesn’t matter if anyone hears it or not.
The other sense of sound is the perception of sound, the way the ear and brain respond and ultimately produce a subjective experience of sound. It is in this sense that a tree falling in a forest with no one to hear it doesn’t make a sound. These two senses overlap but not perfectly. There are physical sounds that are not perceptible. And there are perceptions of sound that don’t directly correspond to any physical kind of sound. This is why it makes sense to speak in terms of different levels of sound that have their own native concepts and vocabularies.
Before getting into these different kinds of musical structures I’d like to propose one more framework for thinking about structures generally in addition to the ideas I got into in the introductory episode. And this is an idea from abstract algebra, a subject I’ll get into in more detail in a later episode. In abstract algebra an algebraic structure is understood to be an arbitrary set, with one or more operations defined on it. Say we have a set of elements. These elements could be anything. And in lumping these elements together we get a set. What other features does this set need to have in order to have structure? For a set that is an algebraic structure it has one or more operations defined on it. So we have to think about what an operation is. Informally, an operation on a set is a way of combining any two elements of the set to produce another element in the same set. More formally – and this will get a little dense here for a moment but bear with me – more formally, let A be any set:
An operation * on A is a rule which assigns to each ordered pair (a, b) of elements of A exactly one element a * b in A.
What this means is that any set with a rule, or rules, for combining its elements, is an algebraic structure. With just a few more conditions, which we’ll bypass for now, such a set is also a group, which is another important kind of algebraic structure. The set is no longer just a collection of unrelated elements. There are rule-like relations between its elements. It’s a way of defining how all its pieces fit together. This is structure. We’ll see quietly nicely in musical structures the way such relations between elements work themselves out. This will be especially evident at the level of musical theory.
But first, let’s look at the acoustics of physical sound. Physical sound is vibration that propagates as a wave of pressure changes through a transmission medium. In general a wave is a propagating dynamic disturbance from equilibrium of one or more quantities. Some quantity is oscillating around the equilibrium position. In the case of a sound wave there is an equilibrium pressure, which would just be the global, average pressure, say in a room or surrounding environment. Then the sound wave is the propagation of variations of the local pressure; parts of the air are compacted, and parts of the air are rarified.
Features of waves include frequency, wavelength, and amplitude. Frequency is the number of cycles per unit time. The Hertz is a common unit for frequency and a Hertz is a cycle per second. So for example, a sound wave with a frequency of 440 Hz, cycles 440 times per second. Wavelength is inversely proportional to frequency; the high frequency sounds have shorter wavelengths and low frequency sounds have longer wavelengths. The constant of proportionality is the speed of the wave’s propagation. So in our case that’s the speed of sound. The equation for this relation is:
fλ = v
Where f is frequency, λ is wavelength, and v is the speed of sound.
The speed of sound is 340 meters per second, with some variation depending on the air conditions. So if a sound wave has a frequency of 440 Hz, i.e. 440 cycles per second, then the wavelength of the wave is 77 cm.
Amplitude is the maximum displacement of a quantity from equilibrium; how high and low the wave goes. For sound the metric used is the sound pressure level. This is the local pressure deviation from the ambient atmospheric pressure, caused by a sound wave. Sound pressure is the difference between the average local pressure and the pressure in the sound wave. When you hear sound volume being spoken of in units of decibels this is what is being quantified. The equation to calculated the sound pressure level in decibels is:
Lp = 20 log10 (p/p0) dB
Where Lp is the sound pressure level in decibels, log10 is a base 10 logarithm, p0 is the ambient pressure, and p is the root mean square sound pressure, which is a function of the amplitude. Basically a sound wave with larger changes in sound pressure will have a higher sound pressure level in decibels.
The behavior of a wave is characterized by the wave equation, which has the following form:
d2u/dt2 = v2 * d2u/dx2
Where x is distance, t is time, and v is propagation velocity. And u is some scalar function of x and t; a multivariable function that depends on more than one variable. The quantity u may be pressure in a medium or the displacement of particles of a vibrating solid, a string for example, away from their resting positions. Both will be relevant to music. Let’s think of it in terms of pressure difference from the mean. This is a second-order partial differential equation, containing second derivatives with respect to distance (d2u/dx2) and with respect to time (d2u/dt2). A differential equation is an equation that relates functions and their derivatives. A derivative gives the rate at which a value changes with respect to some variable. A second derivative repeats this process to give a rate of change of a rate of change. In this case the function is the multivariable function with respect to both distance and time: u(x,t). And because the function u(x,t) is a multivariable function this differential equation is called a partial differential equation. Solving this differential equation is the process of finding the equation for the function u(x,t). In the case of air pressure, solving the differential equation will give us an equation for the air pressure difference from the mean with respect to distance and time.
Coming up with a solution to the wave equation involves specifying certain boundary conditions that will correspond to the physical conditions to which it will apply. For example, if we’re finding a solution for a vibrating string one of the conditions will be the length of the string. So a solution u(x,t) will depend on the precise conditions. I’ll skip over the process of finding a solution, as interesting as that is, and just skip to some examples.
Applying some appropriate boundary conditions one solution to the wave equation is:
u(x,t) = sum( ak * sin(kπx) * cos(kπt),1,∞)
where
ak = 2 * integral( f(x) * sin(kπx) * dx, 0,1)
The solution u(x,t) is a series with a number terms that get added together. Each term in the series gives a harmonic or overtone for the wave and each term in the series has a coefficient that gives them different weights. This is that ak term for the Fourier series coefficient. The complete wave is a superposition of multiple waves that add up linearly. When a string vibrates it’s actually vibrating at multiple frequencies. Using a process of mathematical analysis called Fourier analysis we can break a complete wave into its component waves and see the amplitudes of each frequency. And the breakdown of this Fourier analysis has important implications for the quality or timbre of the sound.
So let’s pause here a moment and think about all this in terms of structure, both to reflect on everything I’ve said so far about physical sound and to think about what I’ll get into next about overtones. We can see here that even with something as seemingly simple as a sound there’s a lot of structure wrapped into it. Let’s think of this in terms of algebraic structures
We start with sets containing elements of values for air pressure, string displacement, distance, and time. So there’s a set for air pressure values, a set for string displacement values, a set for distance values, and a set for time values. Even at this level, before doing anything with these sets it’s worth noting that there’s already structure there. These sets are equipped with operations, so they are also groups. Within each set we can add and multiply values together. But where things get really interesting is where we start to see the structure of the relations between sets, using functions.
A function is a binary relation between two sets that associates every element of the first set to exactly one element of the second set. Functions can also be multivariate and associate more than just two sets. For example, a bivariate function can associate every element of a first set and every element of a second set to exactly one element of a third set. This is what we have with the wave equation and its solution u(x,t). We have the set X of all distance values, x. We have the set T of all time values, t. And we have the set U of all pressure difference values, u. The function u(x,t) takes elements of X and T and assigns each pair (x,t) an element in the set of string displacement values U.
What’s the philosophical significance of that? We can imagine an alternate state of affairs where no such relations obtain. For some system we could have a set of distance values, a set of time values, and a set of pressure difference values with no structure of relations between their elements. That would be much less restricted. Imagine a phase space with all logically possible states of this system. This phase space would not be constrained by physical possibility so we can have any combination of distances, times, and values. We could match any pair of elements (x,t) from sets X and T to any element u, in set U. No restrictions. But the phase space region occupied by physically possible states would be subject to the constraints of the wave function and would be a much smaller region. When the function u(x,t) is applied to the sets X and T every pair (x,t) is matched to only one element, u, in the set U.
There’s also a great deal of structure embedded within most sound waves. A sound wave can be as simple as a pure sine wave. But most sounds are superpositions of multiple frequencies and Fourier analysis allows us to break this down and look at the underlying structure. Recall that the solution to the wave equation is a series of multiple terms. That equation again is:
u(x,t) = sum( ak * sin(kπx) * cos(kπt),1,∞)
This is a series because we add up the terms for each value of k, going from 1 to ∞. For a musical note produced on an instrument, let’s say on a string, the first term will be for the fundamental frequency. The fundamental frequency is the lowest frequency. Musically it’s also the frequency of the musical pitch that we perceive. And this is where we start to slide gradually over into the perception of sound versus just physical sound. For example, an A played on a piano has a fundamental frequency of 440 Hz. But there are also other frequencies produced at several multiples of 440 Hz. And these multiples are the harmonics or overtones. Mathematically these show up in the subsequent terms of the series.
Sine and Cosine are trigonometric functions that oscillate. One interesting feature of these trigonometric functions is that they can be used to approximate any arbitrary function over a certain interval. And for periodic functions, like waves, a summation of trigonometric functions can approximate the entire periodic function. This is the work of Fourier analysis. The series of trigonometric functions is called a Fourier series. This kind of analysis can work in two directions. We can start from the bottom up and build a composite function from sinusoidal components. Or we can start with the composite function and break it down into its sinusoidal components. I’ll focus on the second.
Breaking a sound wave down into its component sine or cosine waves is done using a Fourier transform. One algorithm for this is the Fast Fourier Transform (FFT). We can look at the output of a fast Fourier transform graphically on a FFT spectrum, with frequency on the horizontal axis and amplitude on the vertical axis. This shows how much of each frequency composes the complete wave. The frequencies occur at different amplitudes. The way that these different frequencies add up with different weights affects the way the sound sounds to our ears. This is what we call timbre. Timbre is what’s different between an A played on a piano and an A played on a trumpet. Even though they both have the same fundamental frequency at 440 Hz the amplitudes of their harmonic frequencies compared to the fundamental frequency are quite different. The FFT spectra of an A played on a piano and an A played on a trumpet will look different. And that’s why they sound different.
Let’s look at a few examples. When we play an A on the piano it’s fundamental frequency is 440 Hz. The harmonics will be at 880 Hz, 1320 Hz, 1760 Hz, 2200 Hz, and so on, going up by 440 Hz for each harmonic. Let’s look at the amplitudes of the sound waves at each harmonic, relative to the fundamental. So we’ll say the fundamental frequency has an amplitude of 1 relative to itself. How do the amplitudes of the harmonics compare?
For an A below middle C on a piano, the amplitudes for first few harmonics relative to the fundamental, starting with the first are (in order):
Speaking structurally, each of these spectra is a kind of fingerprint signature that we recognize as having a kind of instrument-specific timbre. These instrumental notes have, in addition to the waveform structure of a single frequency, additional structure composed of multiple frequencies with regular relative amplitudes.
And now let’s move further into the subject of the perception of sound. Our perception of sound depends on a system of anatomical structures, both in the ear and in the brain. We’ll look just at the ear for now. The interesting thing about the ear and our perception of timbre is that our ears basically perform a Fourier transform on the composite sound wave.
The cochlea of the inner ear is a conical structure with varying diameter, getting smaller in diameter spiraling inward toward the apex. The varying dimensions of the cochlea means that different parts of it resonate at different frequencies. So as a sound wave enters the cochlea the component frequencies of the sound wave will cause different parts of the ear to resonate at these component frequencies, but at different amplitudes. The cochlea is effectively performing a Fourier transform by breaking down the composite sound wave into its component frequencies and weighing them by their amplitudes. The basilar membrane then conveys these signals to the brain. In our brains we recognize the different spectra of these sound waves as different instrumental timbres. When the cochlea breaks down a sound wave into its component frequencies we respond to those stimuli in our brain by recognizing them as the sounds made by different instruments: as a piano, or as a guitar, etc. The structure of the sound waves produced by the instruments interacts with anatomical structures in our ear and brain so that we are able to perceive and distinguish different timbers of sound.
This is an interesting example of how, as we translate between physical events and our mental perception of them, the complex structure of the physical event gets embedded in the perception. When we hear an A played on a piano we aren’t consciously aware of all the detailed physical structure discussed here. All of that structure gets wrapped up into a kind of mental module that we perceive as “an A played on a piano”. We perceive that as a musical pitch with the timbre of a certain instrument. The complexity of the structure doesn’t disappear but it gets packaged in a way. And as we move away from the level of physical sound to the level musical theory this becomes very useful. In musical theory we can refer to these pitches on different instruments without having to get into all the structure that goes into them every time. So let’s move to that level now, the level of musical theory.
What are the elements that make up a piece of music? Certainly there are pitches or musical notes. Also durations, timbres, and dynamics, to name a few. Musical composers have at their disposal a wide array of raw materials to work with, to draw upon and organize into an ordered composition.
Let’s look at pitches first. An important feature of pitches is the way they relate to each other. The difference in pitch between two sounds is called an interval. One of the most important intervals is the octave. An octave is the interval between one musical pitch and another with double its frequency. So taking the 440 Hz A pitch, one octave above that would be 880 Hz. This is also an A, but it sounds higher. It is also the first harmonic of the 440 Hz fundamental. The human ear tends to hear both notes as being essentially “the same”, due to closely related harmonics. All octaves are harmonics but not all harmonics are octaves. This is because harmonics increase linearly in frequency but octaves increase exponentially, doubling with each octave. So for example, the first four octaves above 440 Hz are 880 Hz, 1750 Hz, 3520 Hz, and 7040 Hz.
In musical notation pitches separated by an octave are given the same note, so both 440 Hz and 880 Hz are called “A”, though we can distinguish them as A4 and A5 respectively. We can also select pitches between these two pitches to make up a scale. There are various possible scales but let’s look first at the chromatic scale, which includes all the notes of most other scales. A chromatic scale is composed of 12 pitches. These would be all the keys on a piano between octaves; all the white keys and all the black keys. The interval between adjacent pitches in a chromatic scale is a semitone or half step. The difference in frequency between half steps actually increases for higher pitches. Recall that octave frequencies increase exponentially, doubling with each octave. That’s a ratio of 2. For half steps the ratio of frequencies from one to the next is 2^(1/12), which is about 1.059. One important feature of a scale is that when they arrive at the next octave they can be understood to return to their starting point, albeit in a higher octave.
This has the form of modular arithmetic. We can think of the set of pitches as a group of modulo 12. Recall that a group is a set with an operation. Our set has 12 pitches that we can number in this way:
0 = A 1 = A# 2 = B 3 = C 4 = C# 5 = D 6 = D# 7 = E 8 = F 9 = F# 10 = G 11 = G# 0 = A
And with this set we can assign an operation called addition modulo 12. We can label this group Z12. In the operation addition these elements eventually “cycle back” on themselves. A clock face, for example, is also modulo 12. After 12 o’clock there’s no 13 o’clock. You start over again at 1. Similarly, in this group of musical pitches there’s no pitch H. Rather it starts again at A. It’s helpful to visualize this kind of group in a kind of clock face representation, with all the notes arranged a half step apart and then circling back on themselves. In modular arithmetic when you add two numbers h and k you start with h on the clock face and move clockwise k additional units around the circle: h + k is where you end up. For example, 3 + 5 = 7, 7 + 2 = 9. That’s normal. But also, 10 + 5 = 3, 5 + 11 = 4, and 7 + 12 = 7. Those are a little more unusual. But those are the correct sums under this modular arithmetic.
Let’s see how this pertains to some other musical structures. One important musical structure is the melody. Melodies include rhythm as well but let’s just focus on the pitches for now. Melodies include a sequence of pitches. So we’re taking elements from our set of available pitches and arranging them in some new order. For example, the sequences of pitches for “Mary Had A Little Lamb”.
An important feature of such musical melodies is that they can undergo transformations, or in musical terminology, transpositions that preserve the melodic structure, even if they use a different subset of pitches. The melodic structure is invariant under the transformation. For example, let’s add 3 to each element of the melody:
It’s the same melody. It’s just transposed into a different key. The first was in the key of A Major and the second is in the key of C Major. Let’s do another translation that shows the modular arithmetic in particular at work. Let’s add 10 to each element of the first melody:
And this is the melody in the key of G Major. Something to note with this transposition is that adding 10 to most of the elements results in a number “less” than 10 in the regular additive group of integers, Z. But in Z12, the group of integers modulo 12, we see sums like 4 + 10 = 2 and 2 + 10 = 0. Even if a transposition crosses over that point of wrapping back onto itself, it doesn’t matter, under this transposition the structure of the melody is invariant all the same.
We can also look at pitches played simultaneously, which make harmonic intervals (2 notes) or chords (3 or more notes). As with melodies, harmonic intervals and chords can be transposed and still preserve their essential structure. What defines them is not the absolute pitches that compose them but the spacing between them in the Z12 group. For example, the notes in a major third will always be 4 semitones apart, regardless of the specific notes used. The following are examples of major third intervals
{0,4} {A,C#}
{3,7} {C,E}
{5,9} {D,F#}
All have the form {n,n+4}.
Such arrays can have multiple notes to make up chords. Such as a major chord of the form {0,n+4,n+7}
{0,4,7} {A,C#,E}
{3,7,10} {C,E,G}
{5,9,0} {D,F#,A}
Or a dominant seventh chord of the form {0,n+4,n+7,n+10}
{0,4,7,10} {A,C#,E,G}
{3,7,10,1} {C,E,G,B♭}
{5,9,0,3} {D,F#,A,C}
Pitches, along with their arrangements and relations in scales, intervals, and chords, seem to have been the most theorized aspects of musical structure. Or at least I’m most familiar with the theoreticization of these aspects. Other musical elements like rhythm (the duration of pitches), dynamics (volume), timbre, etc. are certainly parts of musical compositions. I won’t get into those in terms of sets, operations, and groups, as I have with pitches, but it’s certainly possible to see, even informally, from the highly ordered form of musical compositions that all these elements are features of musical structure.
For example, the sequence of pitches in “Mary Had a Little Lamb” could have various rhythms. In what is called a 4/4 time signature where a quarter note is equivalent to one beat the traditional melody has the following sequence of note durations:
With some half notes occuring in the sequence. But there are literally infinite possible ways to assign the durations of each pitch. For example, the melody could have this rhythm:
Adding some dotted quarter notes and eighth notes. Those are very common note durations, so nothing too crazy there. But we could, in theory, make these values any real positive number. We could have a note with an irrational duration like the square root of 2 or pi beats, for example. Not that anyone would ever do that. I don’t even know how you’d play something like that. It’s theoretically possible. But in practice we restrict ourselves to an infinitesimal fraction of possible note durations with manageable beat values like 1,2,1/2,1/3,1/16, etc.
Composers can also assign notes, or more commonly whole sections of music, dynamic values or volume levels. These go by names like pianissimo, piano, mezzo-piano, mezzo-forte, forte, fortissimo. And transitions between them like crescendo and decrescendo. Also instructions of articulation like legato, staccato, tenuto, marcato. These are related to duration and dynamics and we might think of them as musical modules into which these structures are embedded for ease of reference. When musicians see a legato marking they already understand intuitively what that means and don’t have to think down to the more basic structures of note duration and dynamics.
So there are a variety of elements on hand to use and arrange into musical compositions: notes, chords, rhythm, dynamics, articulation, timbre, different types of instruments if a composition uses an ensemble. What makes musical composition an art is that we distinguish structured compositions from random assemblages of all these components. Let’s think about the ways structured and “meaningful” musical compositions look in comparison to the set of all possible musical compositions. And this will start to move us into the third level of musical structure: the level of musical expressivity and sensitivity.
Recall from the previous, introductory episode the literary device of the Library of Babel from the short story by Jorge Luis Borges. Let’s adapt that story for musical compositions. We have a library with books containing every possible musical composition. Right away we must see that this library is more complex than Borges’s library of Babel. The Library of Babel was limited to a certain number of characters, arranged unidimensionally. Books in the Library of Babel can’t have more than one character at a time. The characters don’t have different durations, dynamics, or articulations. Maybe that kind of information could be encoded using Borges’s system but musical notation already has that structure embedded into it. A single bar of music, which is a unit of duration in musical time, could have one staff with one note at a time, one staff with multiple notes at a time, multiple staffs for a single instrument – like a piano or organ, or multiple staffs for several instruments – such as in a full orchestra – all playing at once. Just a single beat has myriad possible forms. Since this library is different enough let’s call it the Library of Vienna, in honor of Mozart and Beethoven.
Recall that in Borges’s Library of Babel most of the words were meaningless gibberish. But in that case there was a standard by which to determine whether a string of characters was gibberish or not. Characters would be considered gibberish if they didn’t make up a word in a language. But it wasn’t quite so simple, because there are many languages. So even if a string of characters didn’t make up a word in Borges’s Spanish or in my Enligh, that’s not to say it couldn’t be a word in some other language. Maybe even in a language that doesn’t use a Roman alphabet, since it could be a Romanization, like Pinyin for Chinese. In Borges’s story some of the characters thought they were able to find patterns in other languages.
“For a long time it was believed that these impenetrable books corresponded to past or remote languages. It is true that the most ancient men, the first librarians, used a language quite different from the one we now speak… Five hundred years ago, the chief of an upper hexagon came upon a book as confusing as the others, but which had nearly two pages of homogeneous lines. He showed his find to a wandering decoder who told him the lines were written in Portuguese; others said they were Yiddish. Within a century, the language was established: a Samoyedic Lithuanian dialect of Guarani, with classical Arabian inflections.”
And I just have to insert here that – as a Guarani speaker – I’m a big fan of that part of the story.
So the existence of multiple languages means there are multiple standards of meaningfulness. So that makes the process of discerning meaningfulness more complicated. But in principle there is still a standard. But what about with music? Is there such a standard of meaningfulness for music? Is there some standard by which to say that a composition in the Library of Vienna is complete gibberish? If somebody makes up a word we can easily dismiss it as gibberish, unless for some reason it catches on and becomes a new word. But in music innovation is valued. We value the experience of hearing a melody that we have never heard before and praise composers for producing them. That is, if the new melody is musically pleasing, whatever that might mean. So in one sense the process of discerning meaningful music from musical gibberish is more complicated in the Library of Vienna. But in another sense it might also be easier, if maybe less immediately subjectible to systematization. Whereas for words we have to know all the words in all languages that a string of characters may or may not match, in music the musicality of a melody or more complex composition is more intuitively discerned. There’s no virtual repository of musical “words” that a possible segment has to match. So the actual practice of discerning meaningfulness from gibberish might be easier in the Library of Vienna than in the Library of Babel. But it would seem to be more difficult to rationally reconstruct exactly what that process is and how it actually works.
What are some of the compositions we might find in the Library of Vienna? Some of them are composed by my toddler when she bangs on the piano keys. Some of them are orchestral works for which the parts of each instrument are taken from my toddler’s improvisations. A few very special compositions will be just one note played over and over again. And each of these would have different orchestrations, rhythmic arrangements, and lengths. Some compositions would have all 88 notes on the piano played simultaneously, over and over again, also with different orchestrations, rhythmic arrangements, and lengths. Hidden somewhere in the lightyears of shelving is the score to Beethoven’s Ninth Symphony. Somewhere else is Howard Shore’s score to The Lord of the Rings. And there are also infinite variations on these works, with variations ranging from slight to significant. But the vast majority are completely random compositions, with every possible arrangement of note sequences, chords, orchestrations, rhythms, and lengths.
From one perspective we might say, “What a wealth of fresh and original compositions!” But how much of this music would you like to listen to? I’m pretty sure that, like the residents of Borges’s Library of Babel, we would be much more excited about finding the score to Beethoven’s Ninth Symphony, or even some variation of it, than any given random tome from the shelves. Why? What are the features of Beethoven’s Ninth Symphony that distinguish it from random arrangements of pitches and rhythms? Informally we can say that the Ninth Symphony just has an exceptional degree of musicality. It moves and flows in ways that make musical sense, whatever that might mean.
Are there ways to systematize these kinds of musical, aesthetic intuitions? One way to do this is to pick out patterns in the enduring musical compositions to see what common features characterize our musical grammar. I’ll look at two lists of such features from Roger Scruton and Dmitri Tymoczko.
Roger Scruton in his philosophy talks of music having its own internal logic and moving in its own kind of abstract space called musical space. This musical space has its own set of rules and “physics”, so to speak. Here is a description from Scruton:
“Consider the simple theme that opens Beethoven’s Third Piano Concerto. From the point of view of science this consists of a series of pitched sounds, one after the other, each identified by frequency. But we do not hear a sequence of pitched sounds. We hear a melody, which begins on the first note and moves upward from the C to G, via E-flat, and then stepwise downward to the starting point. But somehow the movement hasn’t stopped, and Beethoven decides to nail it down with two emphatic dominant-tonic commas. Then comes an answering phrase, harmonized this time, and leading up to A-flat construed as a dissonant minor ninth on G. We hear a sudden increase in tension, and a strong gravitational force pulling that A-flat downward on to G, although the melody doesn’t rest there, since it is looking for the answer to the two dominant-tonic commas that we heard earlier, and it finds this answer in another pair of such commas, though this time in the key of G. You could go on describing these few bars for a whole book, and you won’t have exhausted all that they contain by way of musical significance. The point I want to emphasize, however, is that you cannot describe what is going on in this theme without speaking of movement in musical space, of gravitational forces, of answering phrases and symmetries, of tension and release, and so on. In describing the music, you are not describing sounds heard in sequence; you are describing a kind of action in musical space, in which things move up and down in response to each other and against resisting fields of force. These fields of force order the one-dimensional space of music, in something like the way gravity orders the spatiotemporal continuum. In describing pitched sounds as music, we are situating them in another order of events than the order of nature.” (The Soul of the World)
While it may be possible to translate some of these ideas into the language of physics, Scruton seems more or less satisfied with the self-sufficiency and internal coherence of musical space. The notions of “movement in musical space, of gravitational forces, of answering phrases and symmetries, of tension and release” don’t easily map onto other methods of description outside the musical discipline. But they are coherent in that discipline. Scruton doesn’t dismiss other, external descriptions of these things. Rather he valorizes both with what he calls “cognitive dualism”. Even if different methods are incommensurable – not fully intertranslatable – they can still both be accurate for their own purposes, as far as they can go.
An important aspect of Scruton’s philosophy of music, for my purposes, is the role of structure, or organization, in it. And he understands the rules of such organization to be highly delimited, while still permitting endless variety:
“We should recognize here that music is not just an art of sound. We might combine sounds in sequence as we combine colors on an abstract canvas, or flowers in a flowerbed. But the result will not be music. It becomes music only if it also makes musical sense. Leaving modernist experiments aside, there is an audible distinction between music and mere sequences of sounds, and it is not just a distinction between types of sound (e.g. pitched and unpitched, regular and random). Sounds become music as a result of organization, and this organization is something that we perceive and whose absence we immediately notice, regardless of whether we take pleasure in the result. This organization is not just an aesthetic matter, not simply a style. It is more like a grammar, in being the precondition of our response to the result as music. We must therefore acknowledge that tonal music has something like a syntax—a rule-guided process linking each episode to its neighbors, which we grasp in the act of hearing, and the absence of which leads to a sense of discomfort or incongruity.” (The Space of Music: Review Essay of Dmitri Tymoczko’s A Geometry of Music)
I think this idea can help with the Library of Vienna and the reasons for why most of its compositions are not musically satisfying. As in the Library of Babel, compositions in the Library of Vienna can have or not have musical sense. It’s the absence of this musical sense that is gibberish. Musical sense doesn’t translate into semantic sense. Even with program music, in which there is a purported semantic meaning, such meaning doesn’t really come from the music itself. The meaning of music is internal to itself and expressible in its own terms. Scruton lists some structural features of music that give it coherence and musical sense. But before going through Scruton’s list let’s take a look at Tymoczko, who also lists out critical features of Western music and gives an interesting point of musicological comparison.
In his book, A Geometry of Music, Tymoczko lists five features that contribute to a sense of tonality. These are:
Conjunct melodic motion is a term for the way that “melodies tend to move short distances from note to note”. We could think here of the melody in “Mary Had a Little Lamb” as an excellent example of this.
Acoustic consonance is the tendency for consonant harmonies to be preferred to dissonant harmonies, tending to be used as points of musical stability. This has to do with the kinds of harmonic intervals we perceive to be consonant and dissonant. Highly consonant intervals include unisons, octaves, fourths, and fifths. Dissonant intervals include tritones (diminished fifths), minor seconds, and major sevenths. As points of musical stability we can think about the kinds of harmonies on which lines will tend to resolve. The idea of musical resolution actually is this movement from dissonance to consonants. Dissonance will give a sense of being incomplete and the movement to consonance a sense of satisfaction.
Harmonic consistency is the tendency for the harmonies in a passage of music to be structurally similar to each other. Musical compositions will use consonant sequences or dissonant sequences, but not a scrambled mixture of both.
Tymoczko uses the term limited “macroharmony” to refer to “the total collection of notes heard over moderate spans of musical time. Tonal music tends to use relatively small macroharmonies, often involving five to eight notes”. Another way of putting this is that pitches are organized as scales within the octave; they’re in a certain key.
Centricity is the tendency for one note to be heard as more prominent than the others over small spans of musical time. These central notes occur more frequently and serve as a goal for musical motion.
Tymoczko says that his collection of these five components is empirical, theoretical, and historical. We might consider here an analogy to language, playing off Scruton’s idea of musical grammar. Learning a language is taking part in a linguistic tradition or practice. And I think much the same can be said for tonal music. The reason for the prominence of these five features may be partially innate, but regardless they are certainly refined and reinforced by the musical tradition and community of musicians and listeners. Tymoczko has an interesting comment that I think pertains well to the Library of Vienna:
“My central conclusion is that the five features impose much stronger constraints than we would intuitively expect. For example, if we want to combine melodic motion and harmonic consistency, then we have only a few options, the most important of which involve acoustically consonant sonorities. And if we want to combine harmonic consistency with limited macroharmony then we are led to a collection of very familiar scales and modes.”
Because of the strictness of the constraints that these five features impose on tonal music we would expect only an infinitesimal subset of the compositions in the Library of Vienna to conform to these constraints.
Let’s look at the features Scruton picks out for tonal music, or what he calls “diatonic” music, which includes music that uses the major and minor scales as well as various modes, like the Dorian and Phyrgian modes. Scruton lists six features (Music as an Art):
1. Closure 2. The musical boundary 3. The topology of musical space 4. The distinction between (a) subject, thesis, and theme and (b) what is built on it 5. The distinction between harmonies and simultaneities 6. The specific phenomenology of diatonic space
These certainly require some explanation.
By closure Scruton has in mind the tendency of diatonic music to come to points of conclusion or pauses. He compares these to “colons, semi-colons, and full stops”. And there are two reasons for this. The first is that the scale has a point of rest in the tonic. The second is that harmonic progressions can lead to chords without tension; they can resolve. “Hence tonal music admits of both melodic and harmonic cadences – sequences in which accumulated tension is released, as when a suspension is resolved by neighbor-note movement”.
The feature of the musical boundary is very similar to closure but is just the most final form of it, as the ultimate closure of a composition, which defines the temporal stage on which the musical work takes place. “Musical elements in the diatonic language have temporal boundaries: they begin and they end, and between those two points they are in continuous movement. This is true even if there is no sound to be heard. Tonal music moves through silences, and is on its way to closure even when there is nothing to be heard.” It’s worth noting here how this feature of music also gives it a narrative structure, even if the musical meaning is only intelligible in its own terms; it’s only “about” itself. But still there’s a kind of narrative progression, development, and resolution. This kind of narrative structure would be lacking from a random composition in the Library of Vienna.
Scruton says of the topology of musical space: “Thanks to octave equivalence the one-dimensional space of music is folded over at the octave, coming back to its point of departure at every twelfth semitone… it creates a kind of lattice on which melodies and harmonies are arranged and transposed.” This is a point covered under the modular arithmetic of chromatic scales. The modular chromatic scale is a musical structure that supports musical compositions, tonal compositions but also atonal compositions for that matter.
By the distinction between (a) subject, thesis, and theme and (b) what is built on it Scruton is referring to the way musical compositions are often structured to refer back to principle themes on which variations are made. “We recognize the return of the theme, its occurrence in other places, and the various augmentations, diminutions, ornamentations, and variants that made it a mutating presence in the work, a personality that can change its dress and its manner but remain always in essence the same.”
I’d like to dwell on this point a bit because it marks another important feature of structure in music. One very non-random feature of musical compositions is that they tend to contain repetitive elements. We can easily hear this in music containing repeating verses and a chorus. Many songs follow an AABA structure with 2 sections: an A section that occurs twice followed by a second B section before returning again to the opening A section. Think “Over the Rainbow” as an example. There’s a definite narrative arc to that kind of structure.
Twelve bar blues has a similar kind of structure in its chord progression, using tonic (I), subdominant (IV), and dominant chords (V). For example, the progression:
{I7,I7,I7,I7,IV7,IV7,I7,I7,V7,IV7,I7,I7}
Another narrative arc, with a little more complexity, moving first to the subdominant and back down, then to the dominant, and resolving again at the tonic.
The sonata form of classical period music has this similar arc structure. It consists of three main sections: exposition, development, and recapitulation. A theme is presented in the exposition upon which the sonata will be based. A development section elaborates and contrasts with the theme presented in the exposition and this development section can make for some of the most challenging and interesting material in the composition. Be that as it may, it is elevated to a higher energy state that is not restful, and the recapitulation section returns things to the ground state and resolves the piece, not simply as a repetition but as a musical section that functions grammatically as a response and summary of the whole composition. Like in the hero’s journey, the hero returns home, but wiser and more mature.
The fugue is a form with one of the most sophisticated musical structures. Johann Sebastian Bach is rightfully considered the master of this form as found, for example in The Art of Fugue and The Well-Tempered Clavier. These works have variations on a principal subject of increasing complexity. For example, in The Art of Fugue the first four fugues are called “Simple Fugues” on a principal subject. Nevertheless even these simple fugues consist of 4 voices and progressively employ inversions, intense chromaticism, and counter-subjects. All the fugues employ counterpoint, in which two musical lines play against one another and weave together. This is typical of a Bach fugue in which the overwhelming impression is that there’s just a lot going on at once. But there’s a great deal of method in it. Inversion is a kind of rearrangement in intervals, chords, voices, and melodies. In the case of melodies we can think of it as flipping a melody “upside-down” and reversing its contour, a kind of mirror image. And Bach uses this frequently. The later fugues in The Art of Fugue use their principal subjects simultaneously in regular, inverted, augmented and diminished forms (doubling or halving the duration of the notes), and they start including two or three subjects. Musicologist Christoph Wolff said of The Art of Fugue that: “The governing idea of the work was an exploration in depth of the contrapuntal possibilities inherent in a single musical subject.” Bach was pressing the form as far as he could take it.
So all that was to comment on Scruton’s fourth feature of diatonic music: the distinction between the subject, thesis, or theme and what is built on it. Hopefully those examples give an idea of how important and pervasive those are in musical tradition and practice.
Something to consider in terms of structure with all these forms, especially with the fugue, is that there are musical structures that can undergo transformation, much like other kinds of structures, such as vectors or images. With inversions, augmentations, and diminutions the elements of the musical structure are undergoing reflections, expansions, and contractions that preserve the original in recognizable form. That’s part of the idea, to refer everything back to the original. There are changes to the structure but it’s not a random or disjunct transition between unrelated sets of elements. There is order to it. It reminds me of Carl Sagan’s line that “things change alright, but according to patterns, [and] rules”. There’s a non-arbitrariness to the change that makes the term transformation an appropriate description, as something structure-preserving.
The fifth of Scruton’s features of diatonic music is the distinction between harmonies and simultaneities. What is the difference between these? In any composition in our Library of Vienna it’s very likely to have notes occurring simultaneously. This is the toddler banging on the keys or all 88 keys on the piano being played at once. Those are simultaneities. But Scruton is making the case that those kinds of simultaneities are not harmonies. He says: “This is perhaps one of the most important of all the marks of tonality. Tones sounding together strike us only rarely as simultaneous but separate events, and more often as parts of a single complex event.” A C-Major chord, for example, is in one sense a simultaneous occurrence of 3 pitches. But musically we experience it as a single entity, as a C-Major chord to which those 3 pitches belong together as parts of a whole. We might think of this as a kind of embedding or creation of musical modules, similar to the way frequencies and overtones get embedded into musical concepts of notes and timbres.
Scruton’s sixth and final feature of diatonic music was the specific phenomenology of diatonic space. This may be the most interesting and also challenging feature, and it is very characteristic of Scruton’s phenomenological interests. Phenomenology here being the philosophical study of the subjective, first-person experience one has of things, the “what it’s like” quality of an experience. Scruton says of diatonic space and of most musical space in general that “tones seem to move into each other, to compel each other’s appearance, to belong together by a kind of magnetism that makes one tone an introduction to the other and the other a fitting sequel… there is a phenomenological ‘belong together’ that leads us spontaneously to distinguish right from wrong in what we hear.” Recall Scruton’s description of Beethoven’s Third Piano Concerto and its movement through musical space. This kind of abstract space has its own logic and laws with gravitational forces, answering phrases and symmetries, tension and release, and so on.
To give an idea of the unique and self-sufficient nature of musical space I’ll quote another passage from Scruton that I really like:
“Ask yourself just what it is that moves, when music moves. The melody of the Beethoven began on C and moved up to E-flat. But what moved? Not C, which is stuck forever at C. Nor did anything release itself from that C and travel to E-flat—there is no musical ectoplasm that travels across the void between the semitones. If you go on pushing questions like those, you will soon come to the conclusion that there is something contradictory in the idea that a note can move along the pitch spectrum—no note can be identified independently of the place that it occupies, which makes it seem as though the idea of a place is in some way illegitimate. In all kinds of ways musical space defies our ordinary understanding of movement: for example, octave equivalence means that a theme can return to its starting point even though moving constantly upward—a kind of Escher paradox, which has no equivalent in ordinary geometry. Musical space has other interesting topological features. For example, things can rarely be moved through musical space in such a way as to coincide with their mirror image, any more than the left hand, to take Kant’s famous example, can be turned in physical space so as to coincide with the right hand. Thus no asymmetrical chord can be transposed onto its mirror form. The net result of those and similar reflections is to conclude that nothing literally moves in musical space, but that in some way the idea of space cannot be eliminated from our experience of music. We are dealing with an entrenched metaphor—but not a metaphor of words, exactly, for we are not talking about how people describe music; we are talking about how they experience it. It is as though there is a metaphor of space and movement embedded within our experience and cognition of music. This metaphor cannot be ‘translated away,’ and what it says cannot be said in the language of physics—for example, by talking instead of the pitches and timbre of sounds in physical space. Yet what it describes, the musical movement, is a real presence—and not just for me: for anyone with a musical ear.” (The Soul of the World)
This phenomenological structure of music is the most difficult to describe and, if Scruton is correct about cognitive dualism and incommensurability, may have to be described in its own terms. Still the limiting forces of structure seem to apply in this phenomenological space as well. I mentioned in the last episode how some of the criteria distinguishing structure might be more difficult to pin down. David Bentley Hart noted how many aesthetic criteria we might define have a tendency to exclude artistic creations of merit or to include formulaic works without vision. Still, we know that there are such standards. The residents of both the Library of Babel and the Library of Vienna know and feel the differences between the gibberish and the structurally meaningful.
The difficulty of translation between the objective/physical and subjective/phenomenological aspects of structure calls for attention and it’s something I want to think more about and revisit in future episodes. But some ideas occur to me now that I’ll touch on. The basic meta-structure, i.e. the structure of structure, at work at the bridge or gulf between the physical and phenomenological is one in which the operations occurring between inputs and outputs is obscured. There’s a kind homology here to the basic structure of an artificial neural network (ANN). An artificial neural network is a computational model that consists of several processing elements that receive inputs and deliver outputs based on their predefined activation functions. It’s modeled after the biological neural networks that constitute animal brains. But what’s interesting for our purposes here is that the structure of an artificial neural network consists of three basic layers: (1) an input layer, (2) an output later, and (3) a hidden layer.
In a traditional computer programming scheme the pattern is to (1) write the algorithm or rules for the program to follow, (2) feed the program the data to process and, (3) get the desired output. The programming scheme of machine learning works in the other direction. With machine learning you (1) start with the desired output, (2) feed the program the data to process and, (3) have the computer generate the algorithm or rules for the program to follow. This can be a much more convenient scheme for many types of problems. In particular, it works well when you don’t know exactly what the rules should be but you have a pretty good idea of what the general patterns should look like. That actually seems pretty analogous to the gap between the physical and phenomenological conceptions of music.
Let’s look at this from the phenomenological side of the canyon facing the physical side. Why the gap? There are many things that humans are very good at doing without being able to describe what we’re doing. Facial recognition is a good example. We’re really good at it, but we don’t know how we do it. Because we don’t know how we do it, it’s really hard to verbalize an explicit rule that a machine could use to solve the same task. And I think we could say something similar about our aesthetic musical judgment. The fundamental insight of neural networks is that we can represent very big, very general programs capable of making many subtle distinctions, yet in a form that is simple and regular and therefore amenable to
systematic optimization. A neural network consists of (1) units, (2) weighted connections between the units, and (3) activation functions in each unit. This is a very general program but where the specificity can arise is in the weights.
It’s the weights that are adjusted during the learning process and constitutes the generation of new “rules”, so to speak, to achieve the desired outcomes. The networks learn by receiving inputs from examples. While under training, the examples have known inputs and outputs. With these examples the network determines the difference between a processed output from the network and the target output, which is the error. Then the network uses the error to adjust weights assigned to the connections between units. Over repeated training periods and exposure to more examples the network will adjust these weights to better match the target output. Then the idea is that after the training period the network will be able to process real data for which the output isn’t previously known and be able to produce an accurate output, using the weights that were developed during training.
What’s interesting to me about all this in terms of a philosophy of structure is that this kind of process seems to be able to accurately identify what we perceive to be certain kinds of structures without having to give explicit criteria or descriptions of those structures. Nevertheless, there are rules there in the weights. It’s just that those rules take a form that doesn’t easily lend itself to verbal description, much like the phenomenological properties themselves. Still, it does seem to be closer to a kind of bridge between the physical and phenomenological.
The key for me is that the phenomenological aspects of structure cannot be left out. And this brings up an example of structure in musical history that cannot go without mention. And that is the compositional method of serialism. Serialism is highly relevant to the present study because structure is arguably its most salient feature. Serialism is a compositional technique in which a fixed series of notes – and sometimes rhythms, dynamics, timbres or other musical elements – are used to generate the harmonic and melodic basis of a composition and are subject to change only in specific, and heavily rule-governed ways. Twentieth century serialism was highly controversial on many fronts, including in terms of aesthetics. And it makes for an interesting case study on structure and musical aesthetics. In a certain sense no form of music is more structured. Pierre Boulez may be the greatest example of tying every detail of pitch, rhythm, and dynamic down to its most systematized and structured form. He even titled two of his most important compositions Structures I and Structures II. So these cry out for attention under the present discussion.
Both the twelve-tone technique and serialism are easy to criticize but I don’t want to simplistically pile on. This is a subject on which my opinion has changed and Robert Greenberg’s Great Courses series Great Music of the 20th Century was very helpful in that regard. Greenberg shared a few insights that I found very helpful to better appreciate serialism:
1. Even if serialism sounds dated today it served an important role in the historical development of music, which was part of Arnold Schoenberg’s intention from the start.
2. Much serialist music sounds the same and mediocre because, as with all types of music, much of it is mediocre. But…
3. In the hands of certain musical geniuses like Arnold Schoenberg and Igor Stravinsky who, to the somewhat algorithmic nature of the twelve-tone technique also brought consummate musical creativity and sensitivity, serial compositions could be as remarkable and aesthetically estimable as the greatest canonical works.
Arnold Schoenberg felt compelled as a matter of duty to play the role of the great German innovators like Beethoven and Wagner, to break free from the constraints of habit and custom in order to move musical development forward. And he arguably succeeded. But his vision was never about removing the creativity of the composer, removing the human element, from the process of composition. Schoenberg always remained as the flesh-and-blood craftsman of his compositions even as he constrained his compositions according to new structural forms. He continued to shape his music for purposes of eliciting response in the listener. And in this way he was still attuned to the phenomenological aspects of musical structure.
Pierre Boulez had a different vision, aiming to make music much more abstract, incorporeal and removed from the flesh-and-blood world of composers and listeners. He said of his composition Structures:
“I wanted to eradicate from my vocabulary absolutely every trace of the conventional, whether it concerned figures and phrases, or development and form; I then wanted gradually, element after element, to win back the various stages of the compositional process, in such a manner that a perfectly new synthesis might arise, a synthesis that would not be corrupted from the very outset by foreign bodies—stylistic reminiscences in particular.”
Robert Greenberg described music of the type Boulez promoted as “music that is only ‘about’ its compositional process.” In this compositional theory the method is the content. Along similar lines, Ernsk Krenek said, in favor of serialist composition:
“Actually the composer has come to distrust his inspiration because it is not really as innocent as it was supposed to be, but rather conditioned by a tremendous body of recollection, tradition, training, and experience. In order to avoid the dictations of such ghosts, he prefers to set up an impersonal mechanism which will furnish, according to premeditated patterns, unpredictable situations… while the preparation and the layout of the material as well as the operations performed therein are the consequence of serial premeditation, the audible results of these procedures were not visualized as the purpose of the procedures. Seen from this angle, the results are incidental.” (Extents and Limits of Serial Techniques, 1960)
This is about as far removed from Scruton’s phenomenological feature of music as you can go. I’m tempted to say it coheres well with a kind of eliminativist theory of mind that dispenses with notions of self-consciousness and first-person subjective experience. At the very least those are understood to be superfluous to the composition of the music.
Quoting Robert Greenberg again:
“The end result, the actual piece of music, is a manifestation of its formula, and as a result, it is not so much a piece of music as it is a document. Like most conceptual art, the real substance of such a composition lies in its ‘idea’, its formula, its row, rather than in its actual ‘execution’ in real time.”
Well, I said I had no desire to pile on the criticism of serialism. And I really don’t. My point here is not so much criticism of Boulezian serialism as much as the identification of those features that are most salient to the criticisms that have been made. And they are the same features that are not applicable to the most enduring and exceptional works of the serialists for whom the methods still permitted great freedom in which to compose with musical creativity. Both a random composition in the Library of Vienna and the most highly algorithmic and aspirationally composer-less serialist composition might have a high degree of structure in one sense. But high degree of structure and high information content alone don’t translate into high musicality or exhibit the degree of musical structure of the kind described by Scruton and Tymoczko. There are more requirements imposed on musical structures from the boundary conditions of musical space.
So let’s return to the larger project of which this whole discussion of music is a part, a study of structure. What are some features at work here?
One important feature of structure is looking at the parts and the whole, the elements and the sets they compose. We see in music that one example of individual elements is of pitches or notes. And these are basic building blocks of music. Other examples include note durations (units of rhythm), dynamics, and timbre.
Another important feature of structure is the relationship between parts. If a system is structured it is more than a matter of there being multiple parts composing a whole. It’s also a matter of the way the parts relate to each other. In music we have pitches but we also understand these pitches to relate to each other in well-defined ways. They are separated by intervals. They can combine into harmonic intervals and chords. And they wrap back onto themselves across octaves and scales.
Another important feature of structure is embedding. Structures can be embedded as elements into higher structures. They can act as kinds of modules by which the structure of the embedded element can be “called” and run as a kind of subroutine, without having to attend to all the details of the embedded structure. For example, the physical details of a composite sound wave produced by a particular instrument, with its harmonics and Fourier series coefficients, can be wrapped up into a module and embedded as a pitch element in a musical set. Musically we only have to think of it as an “A”, or whatever note it might be. The lower-level structure is still present but it’s conveniently packaged to be used in the higher-level operations.
One final feature of structure mentioned here that I find fascinating and want to explore in more detail later is the kind of structure that spans the gap between the objective/physical aspects of structure and subjective/phenomenological aspects of structure. This is one of the most perplexing features of structure. And it’s this part that overlaps with aesthetic philosophy that is so pertinent to musical structure. In music the important musical structures are not necessarily heavy in information content. They may in fact be highly regular and compressible in terms of information theory. But they are heavy in meaning. And how can that be defined in a rigorous way? Whether or not it ends up being intelligible it may be that some kind of neural-network-like structure, with weights generated through aesthetic training might at least quantify some form of structure that spans this gap.
So that’s an exploration of a philosophy of structure as it pertains to music. I’ll pick up some of the ideas developed here and carry them on to more subjects and continue the process of thinking about the structure of structure.
How can entities be picked out as individual and distinct entities? Sunny Auyang presents a Kantian model of spacetime as an absolute and indispensable structural scheme we project onto the world to organize it and to pick out individual elements, or events in it. Using fiber bundles she packs together a complex structure of individuating qualitative features that she links to individual points in spacetime.
I’d like to talk again about some stuff I’ve been reading in this book by Sunny Auyang, How is Quantum Field Theory Possible? Specifically in this latest chapter I read on the nature of space or spacetime and the possibility of individuation, individuation being the identification and distinction of entities as separate entities.
Both of these issues have a long history in the history of philosophy but Auyang focuses mostly on the work of the modern period of the last few centuries, most especially on Leibniz, Newton, and Kant. There’s a famous dichotomy or division between the models of space put forward by Leibniz and Newton. And the question there is whether space is an independently existing thing or just a way of conceptualizing the relations between actual entities, like their distances and orientations from each other. So Newton’s view was that space has an independent existence. Even if you took out all other entities in the universe space itself would still be there as its own thing. Also time. So both space and time are “absolute”. But for Leibniz these are relative or relational concepts. Lengths, areas, and volumes are relations between entities but if you take away the entities, the actual things there’s nothing left behind, no empty space. Now I’ve read that those are actually drastic simplifications of their views, which doesn’t surprise me. But regardless of that we can at least have those views in mind to start, with the understanding that they’re traditionally associated with Newton and Leibniz. Auyang actually divides both these views further, so that we have four; two Newton-type views and two Leibniz-type views. And I’ll just introduce those so we can use the descriptive names rather than these two proper names.
On the one side we have the substantival view and the absolute view. Spacetime is substantival if it exists independent of material entities. Spacetime is absolute if its concept is presupposed by the concept of individual entities and things. These are similar but slightly different ideas. Substantivalism is ontological, meaning it actually has to do with being, what is. Absoluteness is conceptual; it pertains to the way concepts fit together and what is necessary for certain concepts to work and be intelligible. These can coincide but they don’t have to. And Auyang is going to argue for a model of spacetime that is absolute but not substantival. So in her view spacetime is not a thing that exists independent of material entities but it is a concept that is required to conceptualize material entities.
On the other side Auyang also distinguishes between the relational view and the structural view. I think this is an even more subtle distinction. The difference between these two is a matter of logical priority, looking at what comes first. So recall that with the relational view the concept of space arises from the relations between entities. Dimensions like length, area, and volume are these relations that we perceive between the entities around us. They’re already there and we perceive them. The structural view is the Kantian view, from Immanuel Kant, that space, and we can say also spacetime, are concepts that we project onto the world to organize it bring structure to it. So we as subjects come first. I’m describing that a little differently than she does in the book but that’s the way it makes most sense for me to think about it. And I think it’s consistent with her view. And between these options Auyang is going to argue for a model of spacetime that is structural rather than relational. So it’s more the Kantian model. So bringing these two together her view of spacetime is absolute and structural. In other words, spacetime is a concept that is required for us to conceptualize material entities, and it is a structure that we project onto the world to organize it and make sense of it.
With that in place let’s get to individuation of entities. How do we say that a thing is the same thing across time, something that we can index or label? And how do we say of a thing that it is this thing and not some other thing? “An entity is an individual that can be singly picked out, referred to, and made into the subject of propositions.” Aristotle said that it incorporates two elements. It’s both a this and a what-it-is. These are the notions of individuality and kind. A specific entity is not only a thing but it is this thing. It’s indexed and labeled. It’s also a certain kind of thing. That doesn’t individuate the single entity from other members of that same kind but it distinguishes that class of entities as a kind. Then within that set of that kind of entity they must be further differentiated and identified as individuals. That gets very complex. Other philosophers instead have also argued for the importance of a cluster-of-qualities notion. An entity is no more than the sum of its qualities. If you get specific enough about your qualities maybe that’s all you need. Every entity has a unique spatio-temporal history at least, even if indistinguishable in all other qualities. At least we may so argue. So some important concepts here are individuality, kind, and qualities. These are ways of individuating.
So we’re going to look at a model of these entities. And the first thing to address is that we’re going to look at this through the lens of quantum field theory rather than classical mechanics. So the primary form of matter, the material entities I’ve been talking about before, shift from discrete mass points in space to continuous fields comprising discrete events. Auyang doesn’t mention this but it reminds me a little bit of Alfred North Whitehead’s process philosophy in which he substituted a substance ontology of things to a process ontology of events. Auyang’s quantum field theory is rather different from that, nevertheless, it was something that came to mind. So anyway, the basic entities we’re going to consider now are events.
A field is a continuous system. “The world of fields is full, in contrast to the mechanistic world, in which particles are separated by empty space.” Every point in a field is assigned a value. So say we have a field, that we’ll call the greek letter ψ, for every point x in that field there will be a value ψ(x). And that field variable ψ(x) doesn’t have to be scalar, i.e. just a number. It can be a vector, tensor, or spinor as well. Actually I’m most accustomed to thinking of field variables as vectors like with a gravitational field or an electric field. So with a gravitational field for instance every point in the field around mass M has a vector oriented toward mass M. And then the magnitude of those vectors varies with the distance from mass M. And that’s just an example, the field variable could be any number of things. And that’s important for individuation because we’re going to want to account for the qualities of an individual event with which we can distinguish it. But also one key idea to keep in mind is that the field variable ψ is indexed to some point x in the field. That’s another method of individuation.
So let’s look at how both qualities and numerical identity get taken up in Auyang’s model. To give a bit of a road map before diving into the details her model will include. She’s going to use 6 major pieces: D, G, π, M, x, and ψ.
D is what’s called the total space. G is a local symmetry group. π is a map. M is a base space. x is a position in the base space M. And ψ(x) is an event.
All of this will be put together in a fiber bundle structure. And we’ll get into what all that means in a minute.
First let’s talk about symmetry groups, which will be this G in her model. The concept of the this-something, the individuality of events, is incorporated in field theories through two symmetry groups. Symmetry is a key idea in physics. A related term is invariance, also a very important concept. And it’s basically what it sounds like. It’s some property that doesn’t change. More specifically, we’re interested in the very particular circumstances under which it doesn’t change, called transformations. So you have some object, you transform it in some way – say you rotate it for example – the features that don’t change in that transformation are invariants. And this can tell us important things. The big conservation laws in physics come from invariants as we know from what is called Noether’s Theorem. For example, conservation of energy comes from time invariance. Conservation of momentum comes from translational invariance. Conservation of angular momentum comes from rotational invariance. Very significant. Okay, so backing up again to symmetry groups – that was the whole reason for getting into this. A symmetry group is the group of all transformations under which the object is invariant. Some objects have lots of symmetry – they’ll be invariant under many transformation – others have very little. But the key is that the group of all those transformations where it is invariant – that’s a symmetry group.
The two symmetry groups pertinent to the field theories here are the local symmetry group and the spatio-temporal symmetry group. And these embody different aspects of the individuation of entities. “The idea of kinds is embodied in the local symmetry group, which pertains not to spatio-temporal but to qualitative features. The symmetry group circumscribes a set of possible states and defines a natural kind.” So recall one of the important ideas for identification or individuation was quality. Well the state of an entity covers its qualities. But for localization and identification, its numerical identity, we need a global whole, rather than a local whole, and that is represented by a spatio-temporal symmetry group. “The identities of the events are the invariants in the spatio-temporal symmetry structure.” These two symmetries give us the quality and numerical identity of the entities.
To fit this all together Auyang presents a model for the structure of local symmetries. And she does this using fiber bundles. Fiber bundles are great mathematical tools. The most straightforward way I like to think about fiber bundles is that they are a way to relate single points in some base space to more complex structures in another space. And when I say “space” here these can be abstract spaces, though at least one of these in what follows, the base space, will in fact be a spatio-temporal space. The great thing about this is that it lets us sneak a lot of structure into a spatio-temporal position. And that’s good because we need a lot of structure for these individuating elements. A spatio-temporal position is just one of these individuating elements. We want to bring qualities in there too.
So let’s look at Auyang’s model. This is the featured image for this episode by the way if want to look at it. The objects D, G, and M are differential manifolds, which is basically just a kind of space or surface. These manifolds can be actually spatial or spatio-temporal, which will be the case with our base space M. But they can also be, and often are abstract, which will be the case for our total space D and our local symmetry group G in this model. The first manifold, our total space D, is a set of abstract qualities. So this is where we’re going to get the qualities for our entities from. Then she also has a local symmetry group, G, which is also a manifold. We can label the abstract qualities in D as θ, θ’, and so forth. “At this starting point, both D and G are abstract and meaningless. Our aim is to find the minimal conceptual structure in which we can recognize events as individuals”.
The symmetry group G acts on the total space D and collects subsets of elements in D that are equivalent to each other. Each of these subsets we’ll call a G orbit. The elements in a single G orbit are equivalent to each other. We can start with quality θ and θ’ – those will go into one G orbit. Then we can pick out ξ and ξ’. This divides D up into these G orbit subsets until all elements in D are accounted for. None of resultant G-orbits share common elements. D still has all the same elements as before but they are divided into these subsets. This is quite useful for our purposes of individuation. We have some organization here of all this information.
Next we can take a G orbit and introduce a map π that sends all elements in a G orbit, θ, θ’, for example, sends all those elements onto a single point x. This point x is on another manifold M, a base space. There’s also an inverse map, π-1, that canonically assigns a unique element x in M to each G orbit in D. M is what’s called a quotient of D by the equivalence relation G. It’s not given in advance but falls out from D. Every spacetime point, x, in the spatio-temporal structure, M, is associated with an event, ψ(x), in the total space D. Speaking of this in terms of set theory, D becomes a set with an indexing set M.
So now we have all the pieces put together: D, G, π, M, x, and ψ. And to review, D is the total space, G is a local symmetry group, π is a map, M is a base space, x is a position in the base space M, and ψ(x) is an event. And what’s the significance of all this in the “real world”, so to speak? M is usually called spacetime and x is a point in spacetime, the spatio-temporal position of an event ψ(x). But the identity of an ψ(x) includes more than just it’s spatio-temporal position, even though it’s indexed to that position. All that extra information is in the total space D. It’s divided up by the local symmetry group G. And then it’s mapped onto the spacetime base space M by the map π. The cool thing about the fiber bundle is that it allows us to cram a lot of information into a single point in spacetime, or at least link it to a lot of extra information.
The main goal that Auyang is working toward with this model is individuation. And to do that she needs enough complexity to carry the kind and quality features of individual entities, as well as spatio-temporal position. What happens in this model is that a spacetime position, x, signifies the identity of an event ψ(x). x uniquely designates ψ(x) and marks it out from others. The symmetry group, G, whose features are typical of all ψ(x), signifies a kind; since it collects those features as group. Then the spatio-temporal structure, M, is a system for identifying individuals in that group. So this “sortal concept that individuates entities in a world involves two operations” that will mark out (1) kinds and (2) numerical identity. First the local symmetry group, G, forms identical equivalence classes of qualities for this notion of kinds. Second the projection map, π, introduces numerical identity for each of these equivalence classes. These together secure the individuality of an event, ψ(x).
One thing we can certainly say about this kind of model is that it is analyzable. Events and spacetime positions are not just given in this view. There’s complex interplay between spacetime positions of events and all the qualities of those events. This is what we get with field theories. Even if we look at the world in the most primitive level, as Auyung says, with field theories, “to articulate even this primitive world requires minimal conceptual structure more complicated than that in many philosophies, which regard sets of entities as given.” So is this necessary, are we just making things more complicated than they need to be? Quoting Auyang again: “Field theories have not added complications, they have made explicit the implicit assumptions taken for granted.” I’m not prepared to defend that point but I’m fine with going along with it for the time being.
To wrap things up let’s look at some ways for thinking about this spatio-temporal structure, M. The complexity of the full conceptual structure of this model (D, M, G, π) is what makes it analyzable and it enables us to examine M’s possible meaning. Auyang characteristically promotes a Kantian take on all this. This is to see M as a “scheme of individuation and identification that we project into the world via the inverse map π-1 and by which we present the world to ourselves as comprising distinct entities.” Recall that in Kant’s thought the world is intelligible to us only because we apply categories of understanding to the raw sense data we bring in, and we use these categories to organize it all and make sense of it. Auyung is saying that this is what M does; this is what the spatio-temporal structure, or our concept of spacetime does.
And this idea of space being what individuates things has a long history. For example, speaking of Kant, in Kant’s philosophy space is what makes identity and difference possible. Hermann Weyl called space the “principium individuationis”, which is really fun to say with the classical Latin pronunciation of the ‘v’. But that’s just this idea we’ve been talking about, individuation, the manner in which a thing is identified as distinguished from other things. Weyl also said space “makes the existence of numerically different things possible which are equal in every respect”. So it’s not just the qualities (non-spatial) that are important. You need space to distinguish entities that are otherwise identical. This doesn’t mean that space is substantival, some independently existing substance. But it is conceptually indispensable. So, say it is something that we bring to the scene, something we impose as an organizing tool. It’s still indispensable for the possibility of individuation. So it’s absolute in that sense.
So to review, I’ll put these in Kantian terms. We start off with what is “out there”, just this pre-conceptualized mass of stuff, our total space D. How is that intelligible? We come at it via a conceptual structure, the mental categories of space and time, or spacetime, M. Then we project these spatial and temporal conceptual categories onto the world using the inverse map π-1. This inverse map is able to pick out individual entities in the total space D that are distinguishable by an organizing operation of the local symmetry group G. The local symmetry group G has divided up the total space D into G-orbits with common elements. Our spatial and temporal categories pick these subsets out as events ψ(x) that are mapped onto spacetime M. And that brings the whole structure together in a way that we can see everything together and pick out individual events as individual elements.