
I love nerdy comics like XKCD and Saturday Morning Breakfast Cereal (SMBC). For the subject of this episode I think there’s a very appropriate XKCD comic. It shows the conclusion of a research paper that says, “We believe this resolves all remaining questions on this topic. No further research is needed.” And the caption below it says, “Just once, I want to see a research paper with the guts to end this way.” And of course, the joke is that no research paper is going to end this way because further research is always needed. I’m sure this is true in all areas of science but I think two particular fields it’s especially true. One is in neuroscience, where there is still so much that we don’t know. And the other is evolutionary biology. The more I dig into evolutionary biology the more I appreciate how much we don’t understand. And that’s OK. The still expansive frontiers in each of these fields is what makes them especially interesting to me. Far from being discouraging, unanswered questions and prodding challenges should be exciting. With this episode I’d like to look at evolutionary biology at its most basic, nuts-and-bolts level at the level of chemistry. This combines the somewhat different approaches of both evolutionary biology and molecular biology.

Evolutionary biology benefits from a non-reductionist focus on real biological systems at the macroscopic level of their natural and historical contexts. This high-level approach makes sense since selection pressures operate at the level of phenotypes, the observed physical traits of organisms. Still, it is understood that these traits are inherited in the form of molecular gene sequences, the purview of molecular biology. The approach of molecular biology is more reductionist, focusing at the level of precise molecular structures. Molecular biology thereby benefits from a rigorous standard of evidence-based inference by isolating variables in controlled experiments. But it necessarily sets aside much of the complexity of nature. A combination of these two, in the form of evolutionary biochemistry, targets a functional synthesis of evolutionary biology and molecular biology, using techniques such as ancestral protein reconstruction to physically ‘resurrect’ ancestral proteins with precise molecular structures and to observe their resulting expressed traits experimentally. This enables evolutionary science to be more empirical and experimentally grounded.
In what follows I’d like to focus on the work of biologist Joseph Thornton, who is especially known for his lab’s work on ancestral sequence reconstruction. One review paper of his that I’d especially recommend is his 2007 paper, Mechanistic approaches to the study of evolution: the functional synthesis, published in Nature and co authored with Antony Dean.
Before getting to Thornton’s work I should mention that Thornton has been discussed by biochemist Michael Behe, in particular in his fairly recent 2019 book Darwin Devolves: The New Science About DNA That Challenges Evolution. Behe discusses Thornton’s work in the eighth chapter of that book. I won’t delve into the details of the debate between the two of them, simply because that’s it’s own topic and not what directly interests me here. But I’d just like to comment that I personally find Behe’s work quite instrumentally useful to evolutionary science. He’s perceived as something of a nemesis to evolutionary biology but I think he makes a lot of good points. I could be certainly wrong about this but I suspect that many of the experiments I’ll be going over in this episode were designed and conducted in response to Behe’s challenges to evolutionary biology. Maybe these kinds of experiments wouldn’t have been done otherwise. And if that’s the case Behe has done a great service.
Behe’s major idea is “irreducible complexity”. An irreducibly complex system is “a single system which is composed of several well-matched, interacting parts that contribute to the basic function, and where the removal of any one of the parts causes the system to effectively cease functioning.” (Darwin’s Black Box: The Biochemical Challenge to Evolution) How would such a system evolve by successive small modifications if no less complex a system would function? That’s an interesting question. And I think that experiments designed to answer that question are quite useful.
Behe and I are both Christians and we both believe that God created all things. But we have some theological and philosophical differences. My understanding of the natural and supernatural is heavily influenced by the thought of Thomas Aquinas, such that in my understanding nature is actually sustained and directed by continual divine action. I believe nature, as divine creation, is rationally ordered and intelligible, since it is a product of divine Mind. As such, I expect that we should, at least in principle, be able to understand and see the rational structure inherent in nature. And this includes the rational structure and process of the evolution of life. Our understanding of it may be miniscule. But I think it is comprehensible at least in principle. Especially since it is comprehensible to God. So I’m not worried about a shrinking space for some “god of the gaps”. Still, I think it’s useful for someone to ask probing questions at the edge or our scientific understanding, to poke at our partial explanations and ask, “how exactly?” But, perhaps different from Behe, I expect that we’ll continually be able to answer such questions better and better, even if there will always be a frontier of open questions and problems.
With complete admission that what I’m about to say is unfair, I do think that some popular understanding of evolution lacks a certain degree of rigor and doesn’t adequately account for the physical constraints of biochemistry. Evolution can’t just proceed in any direction to develop any trait to fill any adaptive need, even if there is a selection pressure for a trait that would be nice to have. OK, well that’s why it’s popular rather than academic, right? Like I said, not really fair. Still, let’s aim for rigor, shall we? Behe gets at this issue in his best known 1996 book Darwin’s Black Box: The Biochemical Challenge to Evolution. In one passage he comments on what he calls the “fertile imaginations” of evolutionary biologists:
“Given a starting point, they almost always can spin a story to get to any biological structure you wish. The talent can be valuable, but it is a two edged sword. Although they might think of possible evolutionary routes other people overlook, they also tend to ignore details and roadblocks that would trip up their scenarios. Science, however, cannot ultimately ignore relevant details, and at the molecular level all the ‘details’ become critical. If a molecular nut or bolt is missing, then the whole system can crash. Because the cilium is irreducibly complex, no direct, gradual route leads to its production. So an evolutionary story for the cilium must envision a circuitous route, perhaps adapting parts that were originally used for other purposes… Intriguing as this scenario may sound, though, critical details are overlooked. The question we must ask of this indirect scenario is one for which many evolutionary biologists have little patience: but how exactly?”
“How exactly?” I actually think that’s a great question. And I’d say Joseph Thornton has made the same point to his fellow biologists, maybe even in response to Behe. In the conclusion of their 2007 paper he and Antony Dean had this wonderful passage:
“Functional tests should become routine in studies of molecular evolution. Statistical inferences from sequence data will remain important, but they should be treated as a starting point, not the centrepiece or end of analysis as in the old paradigm. In our opinion, it is now incumbent on evolutionary biologists to experimentally test their statistically generated hypotheses before making strong claims about selection or other evolutionary forces. With the advent of new capacities, the standards of evidence in the field must change accordingly. To meet this standard, evolutionary biologists will need to be trained in molecular biology and be prepared to establish relevant collaborations across disciplines.”
Preach it! That’s good stuff. One of the things I like about the conclusion to their paper is that it talks about all the work that still needs to be done. It’s a call to action (reform?) to the field of evolutionary biology.
Behe has correctly pointed out that their research doesn’t yet answer many important questions and doesn’t reduce the “irreducible complexity”. True, but it’s moving in the right direction. No one is going to publish a research paper like the one in the XKCD comic that says, “We believe this resolves all remaining questions on this topic. No further research is needed.” Nature and evolution are extremely complex. And I think it’s great that Thornton and his colleagues call for further innovations. For example, I really like this one:
“A key challenge for the functional synthesis is to thoroughly connect changes in molecular function to organismal phenotype and fitness. Ideally, results obtained in vitro should be verified in vivo. Transgenic evolutionary studies identifying the functional impact of historical mutations have been conducted in microbes and a few model plant and animal species, but an expanded repertoire of models will be required to reach this goal for other taxa. By integrating the functional synthesis with advances in developmental genetics and neurobiology, this approach has the potential to yield important insights into the evolution of development, behaviour and physiology. Experimental studies of natural selection in the laboratory can also be enriched by functional approaches to characterize the specific genetic changes that underlie the evolution of adaptive phenotypes.”
For sure. That’s exactly the kind of work that needs to be done. And it’s the kind of work Behe has challenged evolutionary biologists to do. I think that’s great. Granted, that kind of work is going to be very difficult and take a long time. But that’s a good target. And we should acknowledge the progress that has been made. For example, earlier in the paper they note:
“The Reverend William Paley famously argued that, just as the intricate complexity of a watch implies a design by a watchmaker, so complexity in Nature implies design by God. Evolutionary biologists have typically responded to this challenge by sketching scenarios by which complex biological systems might have evolved through a series of functional intermediates. Thornton and co-workers have gone much further: they have pried open the historical and molecular ‘black box’ to reconstruct in detail — and with strong empirical support — the history by which a tightly integrated system evolved at the levels of sequence, structure and function.”
Yes. That’s a big improvement. It’s one thing to speculate, “Well, you know, maybe this, that, and the other” (again, being somewhat unfair, sorry). But it’s another thing to actually reconstruct ancestral sequences and run experiments with them. That’s moving things to a new level. And I’ll just mention in passing that I do in fact think that all the complexity in Nature was designed by God. And I don’t think that reconstructing that process scientifically does anything to reduce the grandeur of that. If anything, such scientific understanding facilitates what Carl Sagan once called “informed worship” (The Varieties of Scientific Experience: A Personal View of the Search for God).
With all that out of the way now, let’s focus on Thornton’s very interesting work in evolutionary biochemistry.
First, a very quick primer on molecular biology. The basic process of molecular biology is that DNA makes RNA, and RNA makes proteins. Living organisms are made of proteins. DNA is the molecule that contains the information needed to make the proteins. And RNA is the molecule that takes the information from DNA to actually make the proteins. The process of making RNA from DNA is called transcription. And the process of making proteins from RNA is called translation. These are very complex and fascinating processes. Evolution proceeds through changes to the DNA molecule called mutations. And some changes to DNA result in changes to the composition and structure of proteins. These changes can have macroscopically observable effects.
In Thornton’s work with ancestral sequence reconstruction the idea is to look at a protein as it is in an existing organism, try to figure out what that protein might have been like in an earlier stage of evolution, and then to make it. Reconstruct it. By actually making the protein you can look at its properties. As described in the 2007 Nature article:
“Molecular biology provides experimental means to test these hypotheses decisively. Gene synthesis allows ancestral sequences, which can be inferred using phylogenetic methods, to be physically ‘resurrected’, expressed and functionally characterized. Using directed mutagenesis, historical mutations of putative importance are introduced into extant or ancestral sequences. The effects of these mutations are then assessed, singly and in combination, using functional molecular assays. Crystallographic studies of engineered proteins — resurrected and/or mutagenized — allow determination of the the structural mechanisms by which amino-acid replacements produce functional shifts. Transgenic techniques permit the effect of specific mutations on whole-organism phenotypes to be studied experimentally. Finally, competition between genetically engineered organisms in defined environments allows the fitness effects of specific mutations to be assessed and hypotheses about the role of natural selection in molecular evolution to be decisively tested.”
What’s great about this kind of technique is that it spans a number of levels of ontology. Evolution by natural selection acts on whole-organism phenotypes. So it’s critical to understand what these look like between all the different versions of a protein. We don’t just want to know that we can make all these different kinds of proteins. We want to know what they do, how they function. Function is a higher-level ontology. But we also want to be precise about what is there physically. And we have that as well, down to the molecular level. Atom for atom we know exactly what these proteins are.
To dig deeper into these experimental methods I’d like to refer to another paper, Evolutionary biochemistry: revealing the historical and physical causes of protein properties, published in Nature in 2013 by Michael Harms and Joseph Thornton. In this paper the authors lay out three strategies for studying the evolutionary trajectories of proteins.
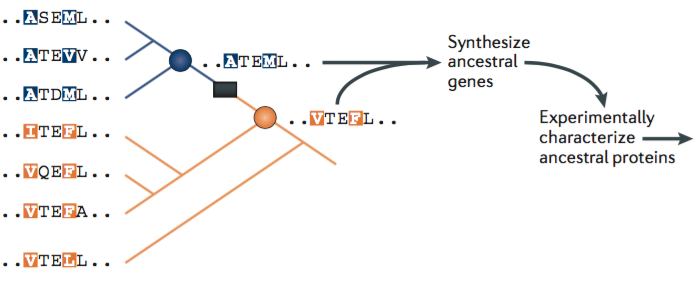
The first strategy is to explicitly reconstruct “the historical trajectory that a protein or group of proteins took during evolution.”
“For proteins that evolved new functions or properties very recently, population genetic analyses can identify which genotypes and phenotypes are ancestral and which are derived. For more ancient divergences, ancestral protein reconstruction (APR) uses phylogenetic techniques to reconstruct statistical approximations of ancestral proteins computationally, which are then physically synthesized and experimentally studied… Genes that encode the inferred ancestral sequences can then be synthesized and expressed in cultured cells; this approach allows for the structure, function and biophysical properties of each ‘resurrected’ protein to be experimentally characterized… By characterizing ancestral proteins at multiple nodes on a phylogeny, the evolutionary interval during which major shifts in those properties occurred can be identified. Sequence substitutions that occurred during that interval can then be introduced singly and in combination into ancestral backgrounds, allowing the effects of historical mutations on protein structure, function and physical properties to be determined directly.”
This first strategy is a kind of top-down, highly directed approach. We’re trying to follow exactly the path that evolution followed and only that path to see what it looks like.
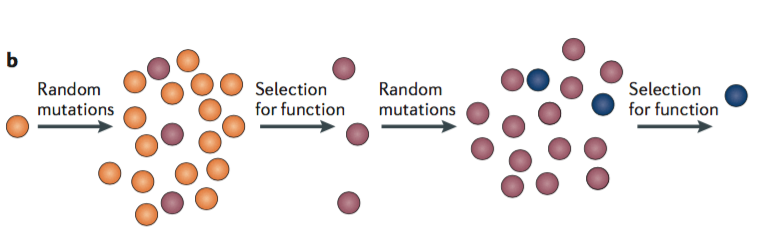
The second strategy is more bottom-up. It is “to use directed evolution to drive a functional transition of interest in the laboratory and then study the mechanisms of evolution.” The goal is not primarily to follow the exact same path that evolution followed historically but rather to stimulate evolution, selecting for a target property, to see what path it follows.
“A library of random variants of a protein of interest is generated and then screened to recover those with a desired property. Selected variants are iteratively re-mutagenized and are subject to selection to optimize the property. Causal mutations and their mechanisms can then be identified by characterizing the sequences and functions of the intermediate states realized during evolution of the protein.”
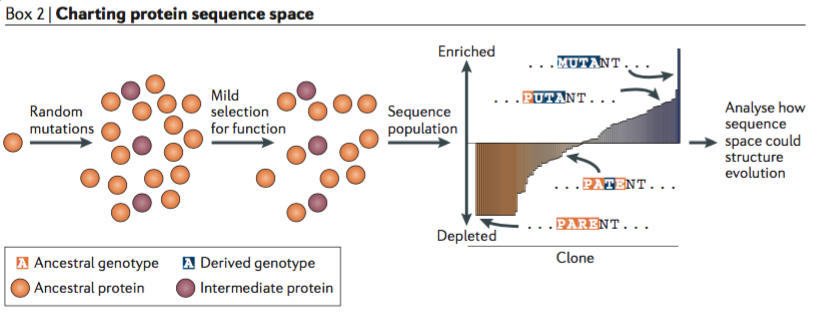
If the first strategy is top-down and the second strategy is bottom-up, the third strategy is to cast a wide net. “Rather than reconstructing what evolution did in the past, this strategy aims to reveal what it could do.” In this approach:
“An initial protein is subjected to random mutagenesis, and weak selection for a property of interest is applied, enriching the library for clones with the property and depleting those without it. The population is then sequenced; the degree of enrichment of each clone allows the direct and epistatic effects of each mutation on the function to be quantitatively characterized.”
Let’s look at an example from Thornton’s work, which followed the first, top-down approach. The most prominent work so far has been on the evolution of glucocorticoid receptors (GRs) and mineralocorticoid receptors (MRs). See for example the 2006 paper Evolution of Hormone-Receptor Complexity by Molecular Exploitation, published in Science by Jamie Bridgham, Sean Carroll, and Joseph Thornton.
Glucocorticoid receptors and mineralocorticoid receptors bind with glucocorticoid and mineralocorticoid steroid hormones. The two steroid hormones studied in Thornton’s work are cortisol and aldosterone. Cortisol activates the glucocorticoid receptor to regulate metabolism, inflammation, and immunity. Aldosterone activates the mineralocorticoid receptor to regulate electrolyte homeostasis of plasma sodium and potassium levels. Glucocorticoid receptors and mineralocorticoid receptors share common origin and Thornton’s work was to reconstruct ancestral versions of these proteins along their evolutionary path and test their properties experimentally.
Modern mineralocorticoid receptors can be activated by both aldosterone and cortisol but modern glucocorticoid receptors are activated only by cortisol in bony vertebrates. So in their evolution GRs developed an insensitivity to aldosterone.
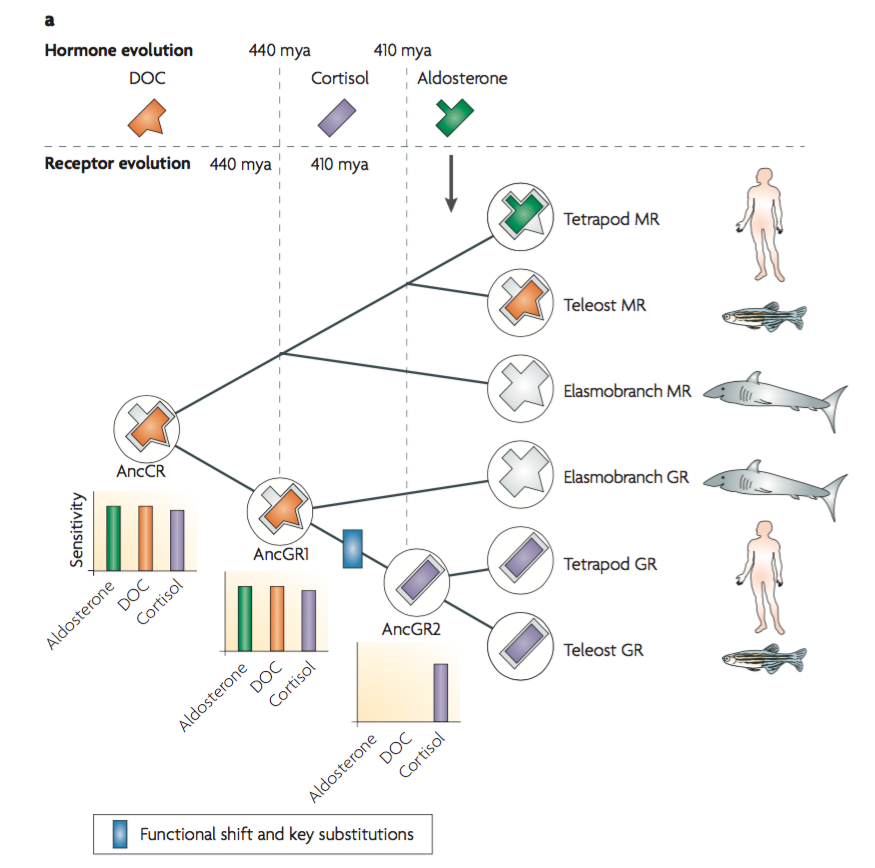
The evolutionary trajectory is as follows. There are versions of MR and GR extant in tetrapods, teleosts (fish), and elasmobranchs (sharks). GRs and MRs trace back to a common protein from 450 million years ago, the ancestral corticoid receptor (AncCR). The ancestral corticoid receptor is thought to have been activated by deoxycorticosterone (DOC), the ligand for MRs in extant fish.
Phylogeny tells us that the ancestral corticoid receptor gave rise to GR and MR in a gene-duplication event. Interestingly enough this was before aldosterone had even evolved. In tetrapods and teleosts, modern GR is only sensitive to cortisol; it is insensitive to aldosterone.
Thornston and his team reconstructed the ancestral corticoid receptor (AncCR) and found that it is sensitive to DOC, cortisol, and aldosterone. Most phylogenetic analysis revealed that precisely two mutations, amino acid substitutions, resulted in the glucocorticoid receptor phenotype: aldosterone insensitivity and cortisol sensitivity. These amino acid substitutions are S106P, from serine to proline at site 106, and L111Q, from leucine to glutamine at site 111. Thornston synthesized these different proteins to observe their properties. The protein with just the L111Q mutation did not bind to any of the ligands: DOC, cortisol, or aldosterone. So it is unlikely that the L111Q mutation would have occurred first. The S106P mutation reduces aldosterone and cortisol sensitivity but it remains highly DOC-sensitive. With both the S106P and L111Q mutations in series aldosterone sensitivity is reduced even further but cortisol sensitivity is restored to levels characteristic of extant GRs. A mutational path beginning with S106P followed by L111Q thus converts the ancestor to the modern GR phenotype by functional intermediate steps and is the most likely evolutionary scenario.
Michael Behe has commented that this is an example of a loss of function whereas his challenge to evolutionary biology is to demonstrate how complex structures evolved in the first place. That’s a fair point. Still, this is a good example of the kind of molecular precision we can get in our reconstruction of evolutionary processes. This does seem to show, down to the molecular level, how these receptors evolved. And that increases our knowledge. We know more about the evolution of these proteins than we did before. That’s valuable. We can learn a lot more in the future using these methods and applying them to other examples.
One of the things I like about this kind of research is that it not only shows what evolutionary paths are possible but also which ones are not. Another one of Thornton’s papers worth checking out is An epistatic ratchet constrains the direction of glucocorticoid receptor evolution, published in Nature in 2009, co-authored by Jamie Bridgham and Eric Ortlund. The basic idea is that in certain cases once a protein acquires a new function “the evolutionary path by which this protein acquired its new function soon became inaccessible to reverse exploration”. In other words, certain evolutionary processes are not reversible. This is similar to Dollo’s Law of Irreversibility, proposed in 1893: “an organism never returns exactly to a former state, even if it finds itself placed in conditions of existence identical to those in which it has previously lived … it always keeps some trace of the intermediate stages through which it has passed.” In their 2009 paper Harms and Thornton and state: “We predict that future investigations, like ours, will support a molecular version of Dollo’s law: as evolution proceeds, shifts in protein structure-function relations become increasingly difficult to reverse whenever those shifts have complex architectures, such as requiring conformational changes or epistatically interacting substitutions.”
This is really important. It’s important to understand that evolution can’t just do anything. Nature imposes constraints both physiologically and biochemically. I think in some popular conceptions we imagine that “life finds a way” and that evolution is so robust that organisms will evolve whatever traits they need to fit their environments. But very often they don’t, and they go extinct. And even when they do, their evolved traits aren’t necessarily perfect. Necessity or utility can’t push evolution beyond natural constraints. A good book on the subject of physiological constraints on evolution is Alex Bezzerides’s 2021 book Evolution Gone Wrong: The Curious Reasons Why Our Bodies Work (Or Don’t). Our anatomy doesn’t always make the most sense. It’s possible to imagine more efficient ways we could be put together. But our evolutionary history imposes constraints that don’t leave all options open, no matter how advantageous they would be. And the same goes for biochemistry. The repertoire of proteins and nucleic acids in the living world is determined by evolution. But the properties of proteins and nucleic acids are determined by the laws of physics and chemistry.
One way to think about this is with a protein sequence space. This is an abstract multidimensional space. Michael Harms and Joseph Thornton describe this in their 2013 paper.
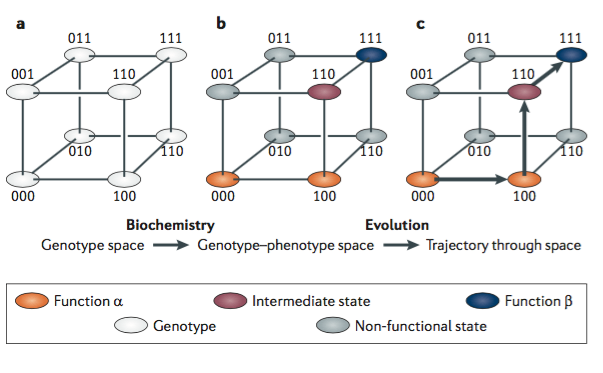
“Sequence space is a spatial representation of all possible amino acid sequences and the mutational connections between them. Each sequence is a node, and each node is connected by edges to all neighbouring proteins that differ from it by just one amino acid. This space of sequences becomes a genotype–phenotype space when each node is assigned information about its functional or physical properties; this representation serves as a map of the total set of relations between sequence and those properties. As proteins evolve, they follow trajectories along edges through the genotype–phenotype space.”
What’s crucial to consider in this kind of model is that most nodes are non-functional states. This means that possible paths through sequence space will be highly constrained. Not just any path is possible. There may be some excellent nodes in the sequence space that would be perfect for a given environment. But if they’re not connected to an existing node via a path through functional states they’re not going to occur through evolution.
To conclude, it’s an exciting time for the evolutionary sciences. If you compare our understanding of the actual physical mechanisms for inheritance and evolution, down to the molecular level we are leaps and bounds ahead of where we were a century ago. Darwin and his associates had no way of knowing the kinds of things we know now about the structures of nucleic acids and proteins. This makes a big difference. It’s certainly not the case that we have it all figured out. That’s why I put evolutionary biology in the same class as neuroscience when it comes to what we understand compared to how much there is to understand. We’re learning more and more all the time just how much we don’t know. But that’s still progress. We are developing the tools to get very precise and detailed in what we can learn about evolution.
